Finding Matching Items on Separate Lists – Bangladeshi Garment Factories
Here’s a question for you – suppose we have two lists:
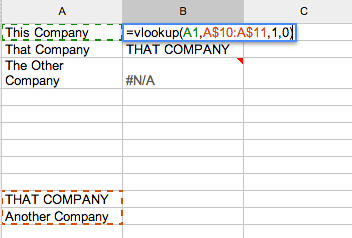
List 1: This Company, That Company, The Other Company
List 2: That Company, Another Company
How would you go about find which companies were in: a) both lists? b) just the first list? Please add your recipe to the comments at the end of this post.
One way is to use a formula such as VLOOKUP in a spreadsheet to try to match each company in the first list with a member of the second list. For example, in Google Spreadsheets or Excel, we could look for exact, case insensitive matches using a formula of the form:
=VLOOKUP(searchterm,match:range,returnColumn,0)
(The final parameter setting – 0 – forces an exact match.)
Another approach might be to use the merge() function in R to see how far we can get trying to merge the two lists:
>a=data.frame(c=c('This Company', 'That Company', 'The Other Company'))
b=data.frame(c=c( 'That Company', 'Another Company'))
merge(a,b,by='c')
c
1 That Company
Yet another approach might be to turn each list into a set and then run set operations on them. In the Python programming language, this might look something like this:
a=set(['This Company','That Company','The Other Company']) b=set(['That Company','Another Company']) a.intersection(b) --Companies in a and in b --set(['That Company']) --Companies in a not in b a.difference(b) --set(['This Company', 'The Other Company'])
Alternatively, in R we can try a similar set based operation along the lines of this:
>b=unique(c('That Company', 'Another Company'))
a=unique(c('This Company', 'That Company', 'The Other Company'))
intersect(a,b)
[1] "That Company"
setdiff(a,b)
[1] "This Company" "The Other Company"
setdiff(b,a)
[1] "Another Company"
Matching company names in this way is easy enough if the company names match exactly, but when dealing with real data, we often find that the way a particular company name is actually recorded may tech various forms.
As an example, let’s consider a couple of datasets that we’re adding to the pool for the upcoming Online Data Expedition: Investigate the Garment Factories, October 18-20. One dataset contains the names of factories used by companies who have signed up to the Accord on Fire and Building Safety in Bangladesh; the second represents a list of member companies of the Bangladesh Garment Manufacturers and Exporters Association (BGMEA).
Looking through the company names listed on the BGMEA members list and the signatories to the Accord, we find exactly these sorts of problem, as well as many more. For example, if we use OpenRefine to try to cluster similar names from the Accord and BGMEA lists, we get the following near matches:
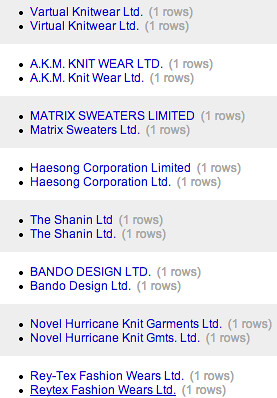
We can then force OpenRefine to set nearly matching names to be exactly the same name (see an example here: School of Data recipe: Cleaning Data with Refine).
In some cases, there may even be legitimate confusion about whether two apparently similar company names do actually refer to the same company or different companies.
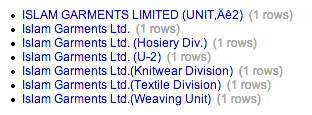
Issues also arise when trying to decide how to refer to things that look like they may be an internal administrative or operational part of a single registered company, or whether they are independently registered companies that may be part of some larger corporate group:
As described in the post On the Need for Corporate Identifiers, what we really need is some way of uniquely identifying companies (and maybe even individual factories too). And as that post suggests, company identifiers such as company registration numbers may be a good candidate for that role.
Fortunately, OpenCorporates have just added a Bangladeshi corporate register to their database, so we can use a tool such as OpenRefine to try to reconcile company names with OpenCorporates company identifiers. More about how to do that in a future post…
![]()