Many times you’ll not have one single page to scrape. For example the Chilean Government has a very nice transparency site and offers the income statistics for many departments – let’s get them all!
To complete this recipe you’ll need:
- The Scraper Extension for Chrome
- A Google Account
- Refine
- If you haven’t yet: Look at the Recipe Scraping websites using the Scraper Extension
To extract information out of multiple web-pages we’ll use a two step procedure: First we’ll get all the URLs for the web-pages with the scraper extension, then we will extract the Information out of these web-pages using Refine. To do this effectively, we rely on all the web-pages to be generated with similar structure. As you’ll see in this Recipe, it is not always the case.
Walkthrough: Getting a list of URLs with scraper extension
-
Open http://www.gobiernotransparentechile.cl/directorio/entidad – the list of government departments in Chile.
-
Mark one department, right click and select “scrape similar…” as in Scraping websites using the Scraper Extension
-
Depending on your selection you might have slightly different results.
-
Now pay attention to the left side of the scraper console – on the top you’ll see a text entry saying XPATH
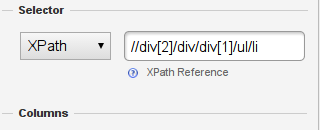
-
The XPATH tells the computer where to find things. The text refers to html tags in the page – let’s modify this to make it work nicely for the page: First remove the [1] behind the second div. This will give you all the texts on the page.
-
Now let’s extract the links from the page. Go back to the page and “inspect” one of the links

-
See how the links are within an <a> element underneath the <li> element? Let’s add this to our xpath.
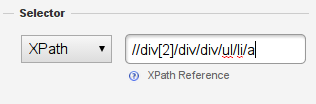
-
We have a column now with the names – if you look closely in the inspected element the <a> tag has two attributes: class and href. Href is the URL and class says something about the category the link belongs to. Let’s extract both.
-
To do so we’ll add more columns to the column list on the second page, do so by clicking the green + next to the one existing column
-
The scraper console wants two things: An Xpath and a name: enter ./@href to the xpath and URL as a name
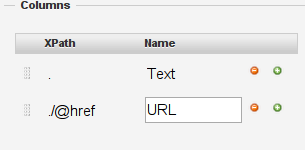
-
Now let’s do the same for the class. Enter ./@class and Class
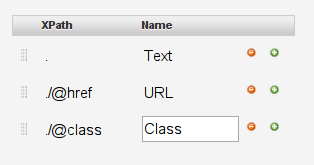
-
Perfect – click on Scrape (or press enter) to see how your list will look like. Nice isn’t it?
-
Now save it to google docs.
Once we have the list of URLs let’s go to Refine to scrape the salary pages we can find easily.
Walkthrough: Scraping multiple pages using Refine
-
Download the Spreadsheet as CSV from google spreadsheets
-
Open Refine – it will open a browser window at http://127.0.0.1:3333
-
Now select Create Project and this Computer
-
Click on Choose Files and select the file you just downloaded.
-
Click Next – this will open the Preview in Refine
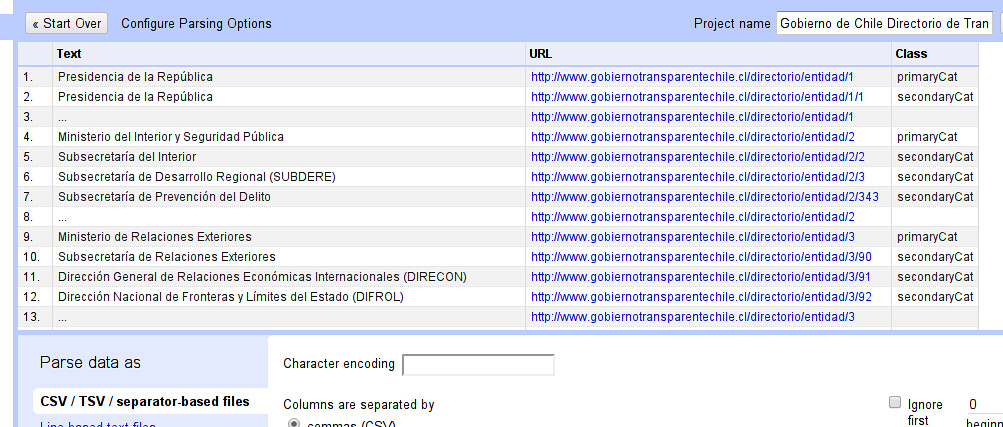
-
Refine should parse the file correctly – name your project on the top right and click Create Project
-
If the special characters in the file look garbled – select UTF-8 as a Character Encoding.
-
You’ll see the data view of Refine. It looks very much like a spreadsheet – and works quite similar.
-
Let’s clean our data and only get the links we’re interested in – the secondary category links
-
Create a filter for the Class column: click on the small triangle next to the column and select Facet -> Text Facet
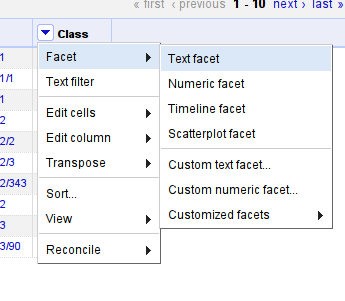
-
This will open a Facet window in the left column that displays all the unique values found within the Class column, along with a count of how many times each of them appear in the column.
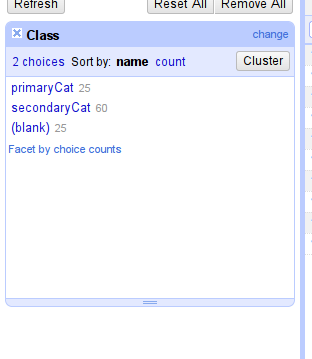
-
Let’s remove everything but secondaryCat. Select secondaryCat in the filter and then click on the small invert label on the top right of the facet.
-
Now let’s remove the rows that are not secondaryCat – for this select the options in the All column and select edit rows – remove all matching rows
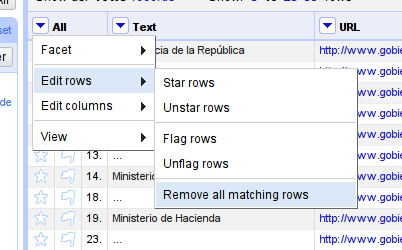
-
Perfect – now we can delete the Class Column, since we’re not going to use it anymore.
-
Do this with the Edit columns -> re-order/remove columns options in the All menu
-
Now let’s scrape the pages. If you look at the page structure, the salary information is often in: /per_planta/Ao-2013 relative to the URL we scraped with the scraper extension.
-
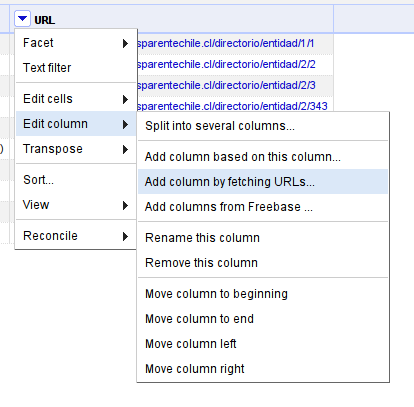
Let’s import the pages – do so by selecting the options of the URL column, and edit column -> add column by fetching URLs
-
This will open an add column menu. We have to transform our cells so that we get the url we want to be fetching.
-
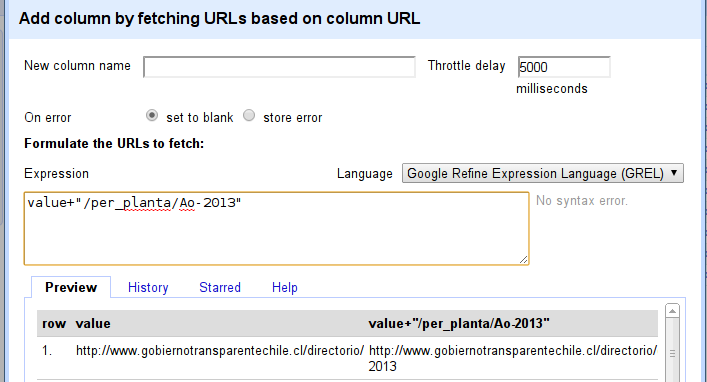
Let’s write our first expression in Refine: we want to append /per_planta/Ao-2013 to each url, so our expression will be value+`/per_planta/Ao-2013` – this appends to the value in the current row.
-
The throttle delay sets the rate at which OpenRefine will request the pages from the webserver they live on. If we try to grab too many pages in a short period of time, the server may lock us out. Requesting 1 or 2 pages a second (throttle delay of 1000 or 500 milliseconds) should be okay in this case. Just be respectful:-). We also need to give the column we’re creating for the scraped data a name – put Page into the column name.
-
click OK – refine will now download the webpages and give you a progress indicator, how it is doing. If you multiply the throttle delay by the number of rows in your dataset, you should get an estimate of the amount of time the download is likely to take.
-
Wooha, this quickly filled our document with HTML code – don’t be intimidated you don’t need to understand or read it – the computer will do this for you.
-
Now let’s first remove all the rows that didn’t get a page (because there is none…) (we could also go and investigate and see whether there’s information we missed – but for the sake of simplicity let’s just delete them).
-
Create a text facet on the Page column, select blank and remove all matching rows as we’ve done above.
-
Close the text facet again to continue working, Now let’s extract the table rows out of each page. Do so by selecting the options of the Page column and edit column -> add column based on this column
-
Name the new column Rows
-
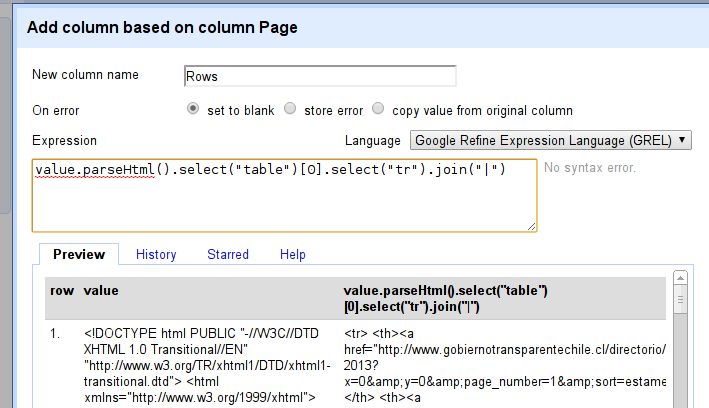
The expression for this is slightly more complicated: first we tell refine that this is an html document we do so by starting with value.parseHtml().
-
Then we append .select(“table”)[0] – this will select the first table from it – see how the content in the new column changes?
-
Now we select all the rows in this column with .select(`tr)` – remember tr is the tag for the rows…
-
This will result in a list of rows – however refine can’t really handle lists. So we have to join the list – so we append .join(“|”) to join the list with a pipe character – the vertical line. (I choose this character because it usually doesn’t appear in the text).
-
Your expression should now look like this:
-
It looks complicated but is actually very simple – it’s just a row of commands – similar to spreadsheet formulas. If you struggle understanding it: Try to read it from the beginning (go back a couple of steps and try to see how the commands are chained together).
-
click OK to fill the Rows column.
-
Now remove the blank rows again as we did before.
-
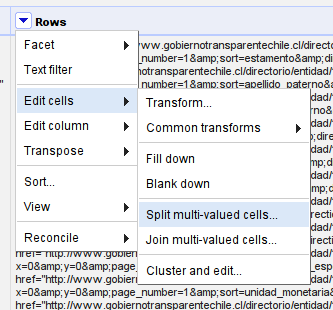
Let’s split the Rows into actual Rows in refine
-
Select Edit Cells -> Split multi-valued cells from the Rows menu
-
A menu will pop up asking us for what kind of character we want to split at: we want to split at |
-
Now let’s extract the data cells in each row. We do this by edit column -> add column based on this column like we did above.
-
Well do value.parseHtml() again – to tell refine this is HTML. Then we .select(“td”) to select the data cells and we’ll join them again with the | character. The expression should look like this:

-
Click OK – you’ll notice now we have quite a bit of blank cells – before we remove them we have to make sure we have the department name with each row. – for this switch back to the column saying Text – this is the department names.
-
Select Edit cells -> fill down from the options menu.
-
This will put the thing it finds in the row into each subsequent empty row until it does find a new filled row.
-
Now you can delete the blank rows.
-
So let’s go back and get the table data out. First we’ll strip the HTML tags from the text, since we don’t need them anymore.
-
We can do so by transforming the cell:
-
Select edit cells -> transform from the options of the Data column.
-
We want to replace anything between pointy brackets with nothing: the expression for this is value.replace(/<.*?>/,””)

-
This has removed the HTML tags. If you look at the data: there is a further problem. A lot of the text has things like Ñ we can parse this automatically
-
Select edit cells -> common transforms -> unescape HTML entities from the options of the Data column – now let’s split the data in this column into multiple columns
-
For this choose edit column -> split into multiple columns and add the | character as the split character for the columns.
-
Now let’s look at what we’ve got: we have multiple columns with the data as presented in the table
-
One of the columns contains the amount – as you can see: it’s not always a number: The multiple . make refine think it’s not a number: let’s fix this: we’re transform the column
-
The expression for this is `value.replace(”.”,””).toNumber()

-
Wonderful – There is still some things wrong: e.g. the special spanish characters don’t translate well – now you know how to use the replace function to replace them.
-
The last thing we do is remove the columns we don’t need anymore: URL , Page and Row
-
Congratulations you’ve scraped and cleaned up a large dataset from several pages on the web.
Last updated on Sep 02, 2013.