Get Started With Scraping – Extracting Simple Tables from PDF Documents
As anyone who has tried working with “real world” data releases will know, sometimes the only place you can find a particular dataset is as a table locked up in a PDF document, whether embedded in the flow of a document, included as an appendix, or representing a printout from a spreadsheet. Sometimes it can be possible to copy and paste the data out of the table by hand, although for multi-page documents this can be something of a chore. At other times, copy-and-pasting may result in something of a jumbled mess. Whilst there are several applications available that claim to offer reliable table extraction services (some free software,so some open source software, some commercial software), it can be instructive to “View Source” on the PDF document itself to see what might be involved in scraping data from it.
In this post, we’ll look at a simple PDF document to get a feel for what’s involved with scraping a well-behaved table from it. Whilst this won’t turn you into a virtuoso scraper of PDFs, it should give you a few hints about how to get started. If you don’t count yourself as a programmer, it may be worth reading through this tutorial anyway! If nothing else, it may give a feel for the sorts of the thing that are possible when it comes to extracting data from a PDF document.
The computer language I’ll be using to scrape the documents is the Python programming language. If you don’t class yourself as a programmer, don’t worry – you can go a long way copying and pasting other people’s code and then just changing some of the decipherable numbers and letters!
So let’s begin, with a look at a PDF I came across during the recent School of Data data expedition on mapping the garment factories. Much of the source data used in that expedition came via a set of PDF documents detailing the supplier lists of various garment retailers. The image I’ve grabbed below shows one such list, from Varner-Gruppen.

If we look at the table (and looking at the PDF can be a good place to start!) we see that the table is a regular one, with a set of columns separated by white space, and rows that for the majority of cases occupy just a single line.

I’m not sure what the “proper” way of scraping the tabular data from this document is, but here’s the sort approach I’ve arrived at from a combination of copying things I’ve seen, and bit of my own problem solving.
The environment I’ll use to write the scraper is Scraperwiki. Scraperwiki is undergoing something of a relaunch at the moment, so the screenshots may differ a little from what’s there now, but the code should be the same once you get started. To be able to copy – and save – your own scrapers, you’ll need an account; but it’s free, for the moment (though there is likely to soon be a limit on the number of free scrapers you can run…) so there’s no reason not to…;-)
Once you create a new scraper:
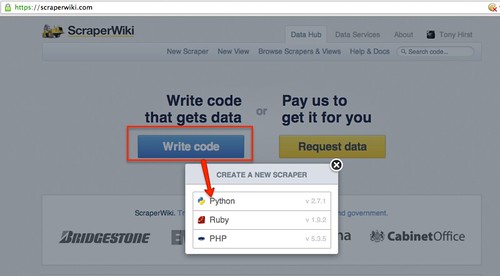
you’ll be presented with an editor window, where you can write your scraper code (don’t panic!), along with a status area at the bottom of the screen. This area is used to display log messages when you run your scraper, as well as updates about the pages you’re hoping to scrape that you’ve loaded into the scraper from elsewhere on the web, and details of any data you have popped into the small SQLite database that is associated with the scraper (really, DON’T PANIC!…)
Give your scraper a name, and save it…
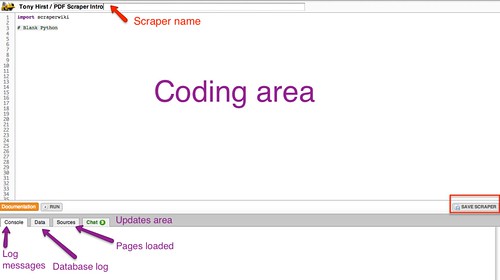
To start with, we need to load a couple of programme libraries into the scraper. These libraries provide a lot of the programming tools that do a lot of the heavy lifting for us, and hide much of the nastiness of working with the raw PDF document data.
import scraperwiki
import urllib2, lxml.etree
No, I don’t really know everything these libraries can do either, although I do know where to find the documentation for them… lxm.etree, scraperwiki! (You can also download and run the scraperwiki library in your own Python programmes outside of scraperwiki.com.)
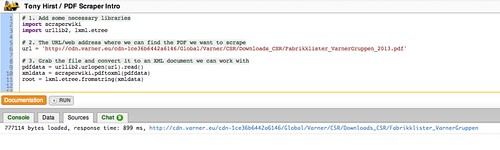
To load the target PDF document into the scraper, we need to tell the scraper where to find it. In this case, the web address/URL of the document is http://cdn.varner.eu/cdn-1ce36b6442a6146/Global/Varner/CSR/Downloads_CSR/Fabrikklister_VarnerGruppen_2013.pdf, so that’s exactly what we’ll use:
url = 'http://cdn.varner.eu/cdn-1ce36b6442a6146/Global/Varner/CSR/Downloads_CSR/Fabrikklister_VarnerGruppen_2013.pdf'
The following three lines will load the file in to the scraper, “parse” the data into an XML document format, which represents the whole PDF in a way that resembles an HTML page (sort of), and then provides us with a link to the “root” of that document.
pdfdata = urllib2.urlopen(url).read()
xmldata = scraperwiki.pdftoxml(pdfdata)
root = lxml.etree.fromstring(xmldata)
If you run this bit of code, you’ll see the PDF document gets loaded in:
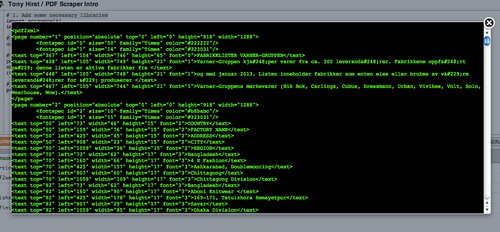
Here’s an example of what some of the XML from the PDF we’ve just loaded looks like preview it:
print etree.tostring(root, pretty_print=True)
We can see how many pages there are in the document using the following command:
pages = list(root)
print "There are",len(pages),"pages"
The scraperwiki.pdftoxml library I’m using converts each line of the PDF document to a separate grouped elements. We can iterate through each page, and each element within each page, using the following nested loop:
for page in pages:
for el in page:
We can take a peak inside the elements using the following print statement within that nested loop:
if el.tag == "text":
print el.text, el.attrib
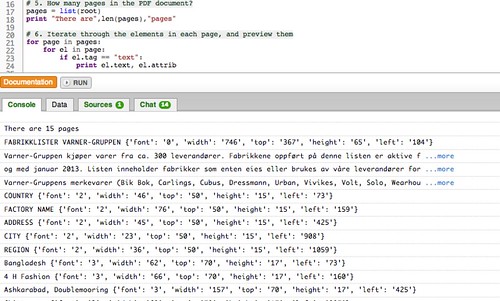
Here’s the sort of thing we see from one of the table pages (the actual document has a cover page followed by several tabulated data pages):
Bangladesh {'font': '3', 'width': '62', 'top': '289', 'height': '17', 'left': '73'}
Cutting Edge {'font': '3', 'width': '71', 'top': '289', 'height': '17', 'left': '160'}
1612, South Salna, Salna Bazar {'font': '3', 'width': '165', 'top': '289', 'height': '17', 'left': '425'}
Gazipur {'font': '3', 'width': '44', 'top': '289', 'height': '17', 'left': '907'}
Dhaka Division {'font': '3', 'width': '85', 'top': '289', 'height': '17', 'left': '1059'}
Bangladesh {'font': '3', 'width': '62', 'top': '311', 'height': '17', 'left': '73'}
Looking again the output from each row of the table, we see that there are regular position indicators, particulalry the “top” and “left” coordinates, which correspond to the co-ordinates of where the registration point of each block of text should be placed on the page.
If we imagine the PDF table marked up as follows, we might be able to add some of the co-ordinate values as follows – the blue lines correspond to co-ordinates extracted from the document:

We can now construct a small default reasoning hierarchy that describes the contents of each row based on the horizontal (“x-axis”, or “left” co-ordinate) value. For convenience, we pick values that offer a clear separation between the x-co-ordinates defined in the document. In the diagram above, the red lines mark the threshold values I have used to distinguish one column from another:
if int(el.attrib['left']) < 100: print 'Country:', el.text,
elif int(el.attrib['left']) < 250: print 'Factory name:', el.text,
elif int(el.attrib['left']) < 500: print 'Address:', el.text,
elif int(el.attrib['left']) < 1000: print 'City:', el.text,
else:
print 'Region:', el.text
Take a deep breath and try to follow the logic of it. Hopefully you can see how this works…? The data rows are ordered, stepping through each cell in the table (working left right) for each table row in turn. The repeated if-else statement tries to find the leftmost column into which a text value might fall, based on the value of its “left” attribute. When we find the value of the rightmost column, we print out the data associated with each column in that row.
We’re now in a position to look at running a proper test scrape, but let’s optimise the code slightly first: we know that the data table starts on the second page of the PDF document, so we can ignore the first page when we loop through the pages. As with many programming languages, Python tends to start counting with a 0; to loop through the second page to the final page in the document, we can use this revised loop statement:
for page in pages[1:]:
Here, pages describes a list element with N items, which we can describe explicitly as pages[0:N-1]. Python list indexing counts the first item in the list as item zero, so [1:] defines the sublist from the second item in the list (which has the index value 1 given that we start counting at zero) to the end of the list.
Rather than just printing out the data, what we really want to do is grab hold of it, a row at a time, and add it to a database.
We can use a simple data structure to model each row in a way that identifies which data element was in which column. We initiate this data element in the first cell of a row, and print it out in the last. Here’s some code to do that:
for page in pages[1:]:
for el in page:
if el.tag == "text":
if int(el.attrib['left']) < 100: data = { 'Country': el.text }
elif int(el.attrib['left']) < 250: data['Factory name'] = el.text
elif int(el.attrib['left']) < 500: data['Address'] = el.text
elif int(el.attrib['left']) < 1000: data['City'] = el.text
else:
data['Region'] = el.text
print data
And here’s the sort of thing we get if we run it:
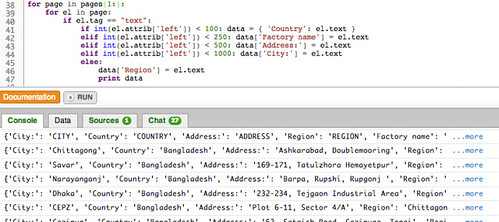
That looks nearly there, doesn’t it, although if you peer closely you may notice that sometimes we catch a header row. There are a couple of ways we might be able to ignore the elements in the first, header row of the table on each page.
- We could keep track of the “top” co-ordinate value and ignore the header line based on the value of this attribute.
- We could tack a hacky lazy way out and explicitly ignore any text value that is one of the column header values.
The first is rather more elegant, and would also allow us to automatically label each column and retain it’s semantics, rather than explicitly labelling the columns using out own labels. (Can you see how? If we know we are in the title row based on the “top” co-ordinate value, we can associate the column headings with the “left” coordinate value.) The second approach is a bit more of a blunt instrument, but it does the job…
skiplist=['COUNTRY','FACTORY NAME','ADDRESS','CITY','REGION']
for page in pages[1:]:
for el in page:
if el.tag == "text" and el.text not in skiplist:
if int(el.attrib['left']) < 100: data = { 'Country': el.text }
elif int(el.attrib['left']) < 250: data['Factory name'] = el.text
elif int(el.attrib['left']) < 500: data['Address'] = el.text
elif int(el.attrib['left']) < 1000: data['City'] = el.text
else:
data['Region'] = el.text
print data
At the end of the day, it’s the data we’re after and the aim is not necessarily to produce a reusable, general solution – expedient means occasionally win out! As ever, we have to decide for ourselves the point at which we stop trying to automate everything and consider whether it makes more sense to hard code our observations rather than trying to write scripts to automate or generalise them.

The final step is to add the data to a database. For example, instead of printing out each data row, we could add the data to the a scraper database table using the command:
scraperwiki.sqlite.save(unique_keys=[], table_name='fabvarn', data=data)

Note that the repeated database accesses can slow Scraperwiki down somewhat, so instead we might choose to build up a list of data records, one per row, for each page and them and then add all the companies scraped from a page one page at a time.
If we need to remove a database table, this utility function may help – call it using the name of the table you want to clear…
def dropper(table):
if table!='':
try: scraperwiki.sqlite.execute('drop table "'+table+'"')
except: pass
Here’s another handy utility routine I found somewhere a long time ago (I’ve lost the original reference?) that “flattens” the marked up elements and just returns the textual content of them:
def gettext_with_bi_tags(el):
res = [ ]
if el.text:
res.append(el.text)
for lel in el:
res.append("<%s>" % lel.tag)
res.append(gettext_with_bi_tags(lel))
res.append("</%s>" % lel.tag)
if el.tail:
res.append(el.tail)
return "".join(res).strip()
If we pass this function something like the string <em>Some text<em> or <em>Some <strong>text</strong></em> it will return Some text.
Having saved the data to the scraper database, we can download it or access it via a SQL API from the scraper homepage:
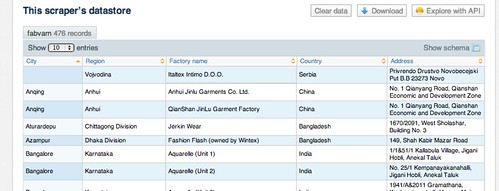
You can find a copy of the scraper here and a copy of various stages of the code development here.
Finally, it is worth noting that there is a small number of “badly behaved” data rows that split over more than one table row on the PDF.

Whilst we can handle these within the scraper script, the effort of creating the exception handlers sometimes exceeds the pain associated with identifying the broken rows and fixing the data associated with them by hand.
Summary
This tutorial has shown one way of writing a simple scraper for extracting tabular data from a simply structured PDF document. In much the same way as a sculptor may lock on to a particular idea when working a piece of stone, a scraper writer may find that they lock in to a particular way of parsing data out of a data, and develop a particular set of abstractions and exception handlers as a result. Writing scrapers can be infuriating at times, but may also prove very rewarding in the way that solving any puzzle can be. Compared to copying and pasting data from a PDF by hand, it may also be time well spent!
It is also worth remembering that sometimes it can be quicker to write a scraper that does most of the job, and then finish off the data cleansing or exception handling using another tool, such as OpenRefine or even just a simple text editor. On occasion, it may also make sense to throw the data into a database table as quickly as you can, and then develop code to manage a second pass that takes the raw data out of the database, tidies it up, and then writes it in a cleaner or more structured form into another database table.
The images used in this post are available via a flickr set: ScoDa-Scraping-SimplePDFtable
![]()