Civic tech in the Balkans

Last week the Community Boost_r program brought together information and technology activists from Eastern Europe in an un-conference style tech camp in Sarajevo. The camp featured two days packed with workshops and plenty of opportunity to nerd around. Milena and Michael were there for School of Data to run a data expedition and give a hands-on introduction into data-cleaning with Refine.
##Investigating election data in Montenegro and Bosnia
The first session we organized was a data expedition. Since elections are a hot topic in the region, we chose to work on two interesting datasets: one from Bosnian local elections and one from presidential and parliamentary elections in Montenegro. We worked in small looking at the different data we had.
The first group looked at a dataset of local elections in Bosnia obtained via FOIA by OneWorld SEE and containg detailed data on all candidates for the past 3 local elections (2004, 2008 and 2012). After a quick look at the data, the group decided to focus on 2 issues: gender representation and the degree to which the same candidates run for office several times. In the gender group we quickly realised there is a 33% compulsory quota of women candidates which all parties strictly abide by. However, only 5% of women candidates end up being elected. But the most interesting thing in the data was the little variation over year and parties – it was almost like there was a mastermind engineering the data.
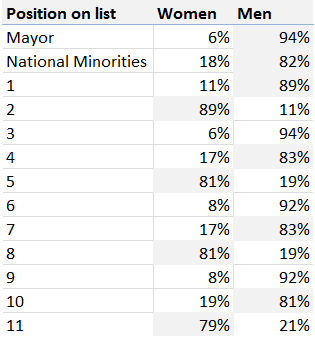
This mathematical precision showed up also when we tried to analyse on which positions are women more likely to be placed on a list. With no variation across political parties or years, it seems like women are overwhelmingly placed on positions 2, 5, 8 and 11 and of course few of them are candidates for mayor positions: 6% of total candidates and only 3% of elected mayors.
Over in the Montenegro group the participants quickly decided on wanting to do cluster-analysis of the existing data – to find clusters of districts that vote similarly. They found a quite strong difference between voting patterns in Podgorica and the rest of the country: rural to urban differences seem to be the cause here.
##Cleaning Data with Refine – hands on
Thanks to having too many ideas when asked out on an event we planned a session on Data cleaning with Refine for the second day. As this is a quite nerdy topic you can’t expect too many people when at the same time sessions discuss how to kick your local governments seating muscles. Nevertheless, a small, engaged crowd of people showed up and we took them through cleaning a dataset of bosnian tender information. (Walkthroughs available here). On the way through the workshop we took a small detour through regular expressions – a very handy special expression language to search text for specific patterns.
What we’ve learned
Besides the oddities of the election system in Bosnia and Herzegovina we met a large group of people involved in improving the communication of their citizens with municipal, local and federal governments. While the patterns seem very similar – the projects tend to replicate similar projects over and over again. A problem that seems to be slowly recognized in the community. The same is true for data: while some projects aim to bring together various civil society organizations to share their data – many start building their own codebase. We need to start sharing! If we work together collaboratively, we can achieve so much more.
![]()