PDFs can be all forms and shapes – if you’re facing a nicely formatted PDF that is not scanned give Tabula a shot to extract the information. How? read the short walkthrough below:
You’ll need:
- Tabula http://tabula.nerdpower.org
- a PDF: e.g. http://www.unhabitat.org/pmss/getElectronicVersion.aspx?nr=3387&alt=1
Waltkthrough: Extracting data from PDF tables
-
Download the PDF at:: http://www.unhabitat.org/pmss/getElectronicVersion.aspx?nr=3387&alt=1
-
Start Tabula (most likely by double clicking on the tabula icon)
-
point your browser tof http://127.0.0.1:8080
-
Choose the file you want to upload and click Submit
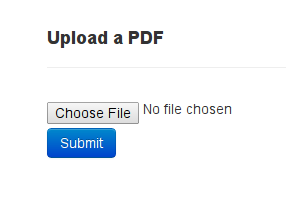
-
Wait until the PDF is fully loaded
-
Scroll down to page 167 – we’ll extract that table.
-
Click and pull a selection box over the table
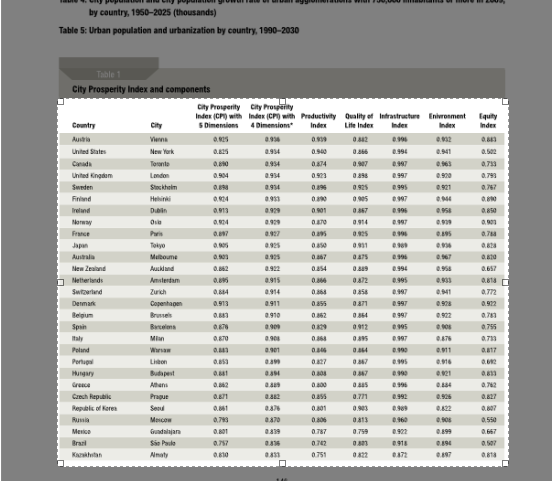
-
A window will pop up to show how Tabula would extract the data.
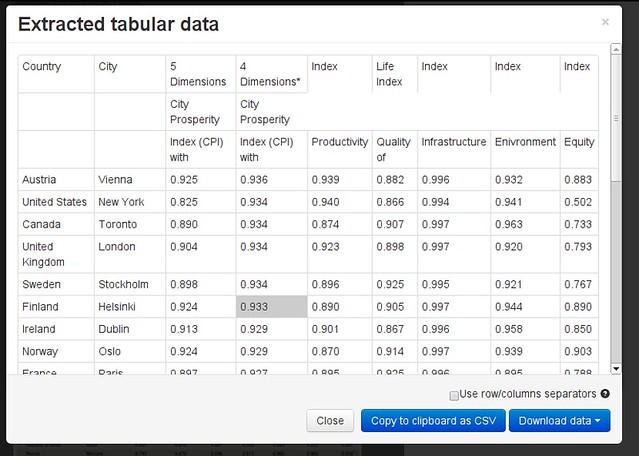
-
Now download the Data as CSV
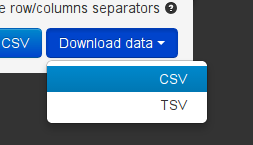
-
Fantastic you liberated the table from the PDF. Quick and easy wasn’t it?
Last updated on Sep 02, 2013.