Getting data from websites might seem a little complicated at first – but rest assured, once you’ve done it a couple of times it will be similar. To extract data from websites we need to peek under the hood and look at the underlying HTML code. Don’t worry you don’t need to understand every detail of it just to be able to do so.
HTML is the acronym for Hypertext Markup Language and is the language used to describe (markup) web pages. It is the underlying language to structure web-page content. HTML itself does not determine the way things look – it only helps to classify and structure content. So let’s peek at some websites.
Walkthrough: Exploring HTML with Google Chrome
-
Open the website listing all MPs for the UK Parliament at http://www.parliament.uk/mps-lords-and-offices/mps/ in Chrome
-
Scroll down to the list of MPs
-
Right click on one of the entries
-
Select “Inspect Element”
-
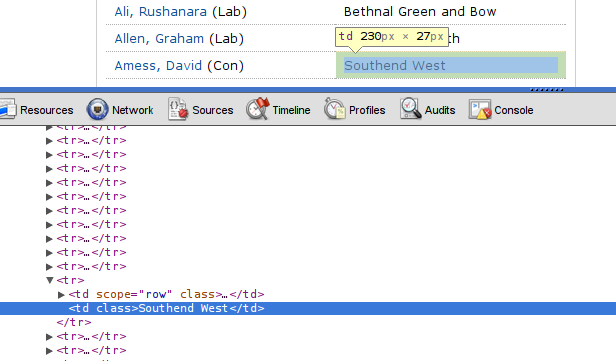
Chrome will open a second area on the bottom of the page showing the underlying HTML code – focussed on the element you clicked
-
The pointy brackets are the HTML tags.
-
Now move your mouse up and down and notice how chrome tells you which element is which
-
You can expand and collapse certain sections by clicking on the triangles
-
Did you notice something? Every row in the long list of MPs is within one <tr></tr> section. <tr> indicates a table row.
-
The names and the constituency are in <td></td> tags – td indicates table data. So we’re dealing with a table here?
-
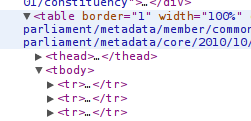
If you scroll up the list you’ll notice a <table> element, followed by a <tbody> element – so yes this is a proper HTML table.
-
Go ahead and explore!
HTML is no mystery. If you want to know more about it and how to build webpages with it – visit the School of Webcraft for a gentle introduction.
Other browsers
To do the same thing in other browsers, try the following approaches.
- Firefox: Install Firebug plugin (http://getfirebug.com/)
- Safari: Preferences > Advanced > Show Develop Menu > Show Web Inspector
- Internet Explorer 7: Install Developer toolbar
HTML Elements
Elements are identified by ‘tags’, their name. They can have an inner text and “attributes” (named properties): <tag attribute=”value”>text</tag>
- <html> – the whole document
- <body> – the human-readable part of the web page
- <table> – the frame of a table element
- <tr> – a row in a table
- <td> – a cell of content inside a row
- <th> – a table header cell inside a row
Python code elements for scraping
- name = expression – assign a name to the output of a computation
- from lxml import html – import html component form a “library”
- doc = html.parse(‘http://….’) – download and analyze a web page.
- doc.findall(‘//tag’) – find all occurrences of a tag in the whole document
- element.findall(‘childtag’) – find all othertags within element
- element.find(‘highlander’) – find a single highlander within element
- for name in list-of-things: – run code on each element of the list, assign the item to name
- list-name[n] – get the nth element from a list.
- scraperwiki.save(unique_keys=[], data={‘field’: value, ‘field2’: value} – see https://scraperwiki.com/docs/python/python_datastore_guide/
Task: Pick a website and look at the HTML code using Inspect Element. Did you find something interesting?
.. raw:: html
Last updated on Sep 02, 2013.