This module provides a brief overview of the different techniques used to extract data from PDFs, with a focus on introducing Tabula, a free open-source tool build for this specific task.
Modules Objectives
- Discovering the different techniques available for extracting PDFs
- Learning how to use Tabula to extract data from PDFs
Prerequisites
- None
Introduction
Do you want a document that is secured, difficult to edit, easily compressed and portable? If so, please stick with PDFs. But at a time when the world is moving toward collaborative practices with data at the core of this movement, how can we keep it locked in a Portable Document Format, difficult to reach?If you have faced the challenge of having to extract data from a pdf, this tutorial is for you. If you haven’t, read on anyway because if you want to keep up with the growing trend of data, extracting is something you should know.
Extracting data from PDF can be done with…
- PDF to Word/Excel converters which allow you to copy the information you need. But the result is often messy if there are tables in the pdf. Some free tools include Excel Online
- OCR (Optical Character Recognition) which “reads” the PDF and then copy its content in a different format, usually simple text. Quality varies between the OCR engines, and often the licences are not free. You could always go with the free and open source Tessaract OCR, but it requires some programming know-how.
- Programming, with some libraries existing for Python (PDFMiner), Java (TIka, PDFBoc), and the command line (pdftotext, pdftohtml).
- Crowdsourcing, which is not specifically for PDF, but can be used when you have many documents to transcript.
- and Tabula, the new kid on the block, specifically designed to get data out of PDF tables, which is often where the data you’re looking for lives.
The tabula way
What is Tabula and how does it work?
Tabula is an offline software, available under MIT open-source license for Windows, Mac and Linux operating systems, that allows you upload a PDF file and extract a selection of rows and columns from any table it may contain.
Getting Tabula
Tabula is available for the 3 major operating systems. Download it for Windows, Mac and Linux . It works in a java environment so you will have to download java runtime environment if you don’t already have it.
Note: Tabula for Mac OS X comes with Java
Tips for installing
- Once the program is downloaded, you are halfway toward your first table extraction. Follow these steps to get Tabula set up and ready to go.
- Your downloaded file would be a zip file, so extract the folder within
- Go into the extracted folder and run the Tabula program in it
- It should automatically open in your browser (chrome, firefox, safari are all confirmed browsers that work)
- If it does not launch on you browser, use this URL – http://localhost:8080
You should now see the user interface of Tabula.
Extracting your table
Tabula is a pretty easy application to use once installed. This steps should see through the process:
- Upload your PDF file: Run the application file in your extracted folder. Tabula should launch and show the interface in figure 1 below. click on the Browse button as highlighted on the image to select among your documents the PDF you want to extract from. Here is an example pdf that you could use. The uploaded file should show on the right hand side as shown in Figure 1.
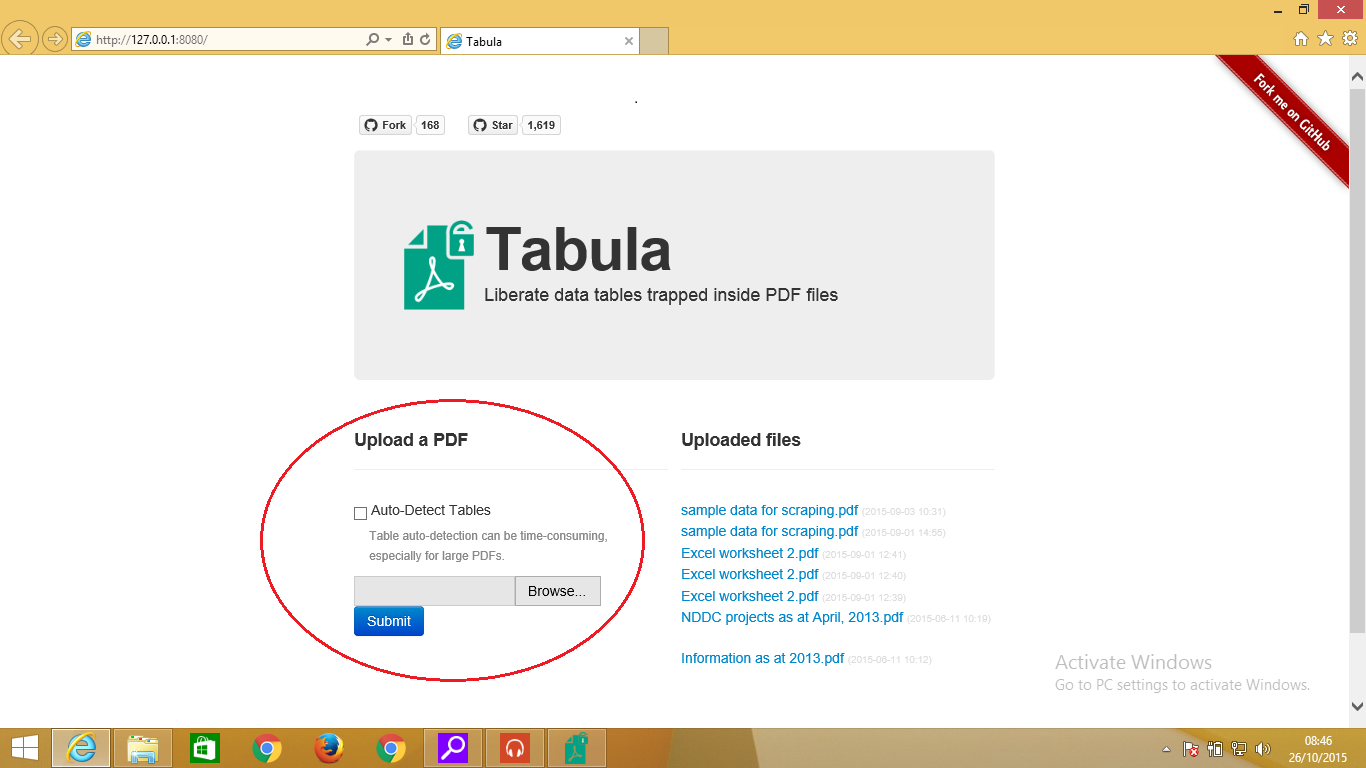
Tabula User Interface
- Viewing the PDF document for Extraction: From the same screen seen in Figure 1, click on your uploaded file and you should get a view like Figure 2 below. Select the section of the table you want to extract, or select all if you are extracting the full table. Note: you can always adjust your selection.
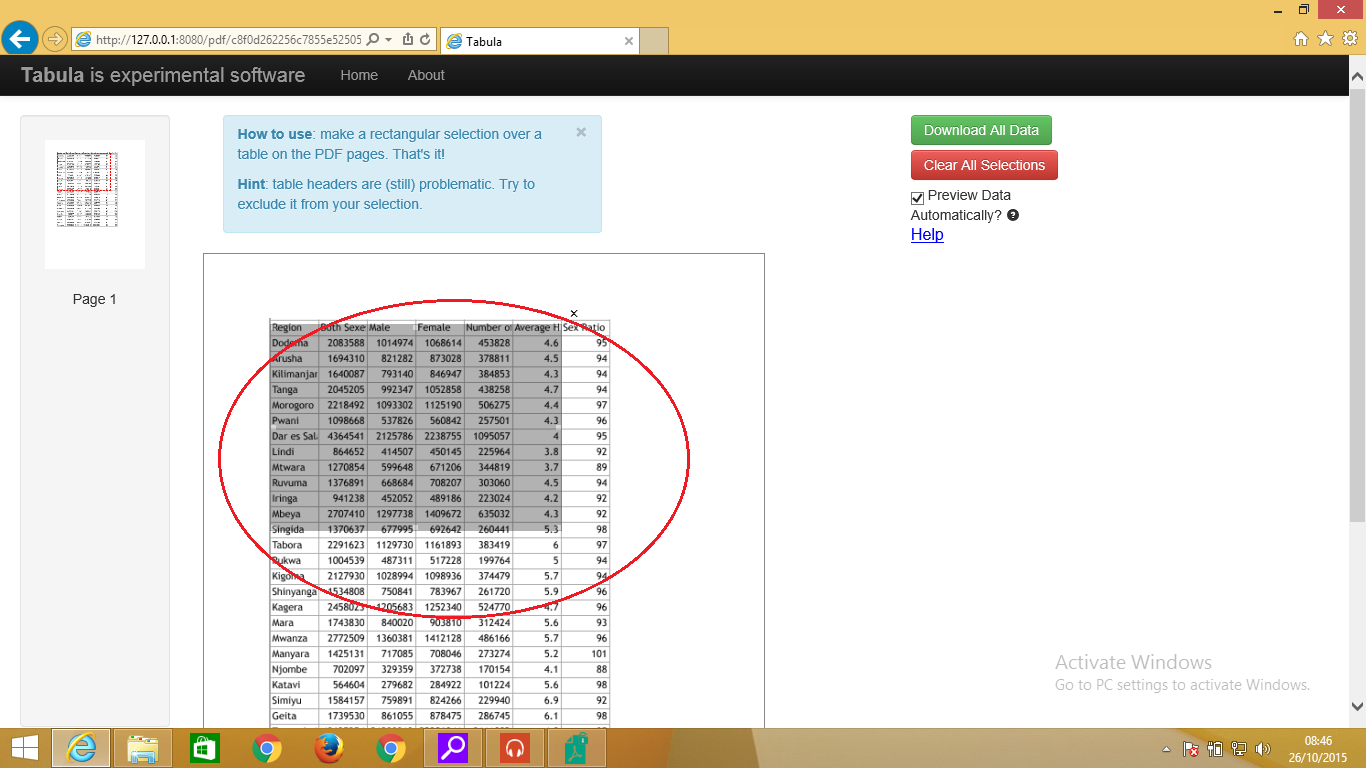
Selecting the table to extract
- Exporting the data: Immediately after making your selection, your data should immediately show in a similar screen like Figure 3 below. You have an option to copy to clipboard and paste wherever you like or download your CSV file which can be opened in any spreadsheet application (Microsoft Excel, LibreOffice Calc, Google Spreadsheet…).. Simple and easy!
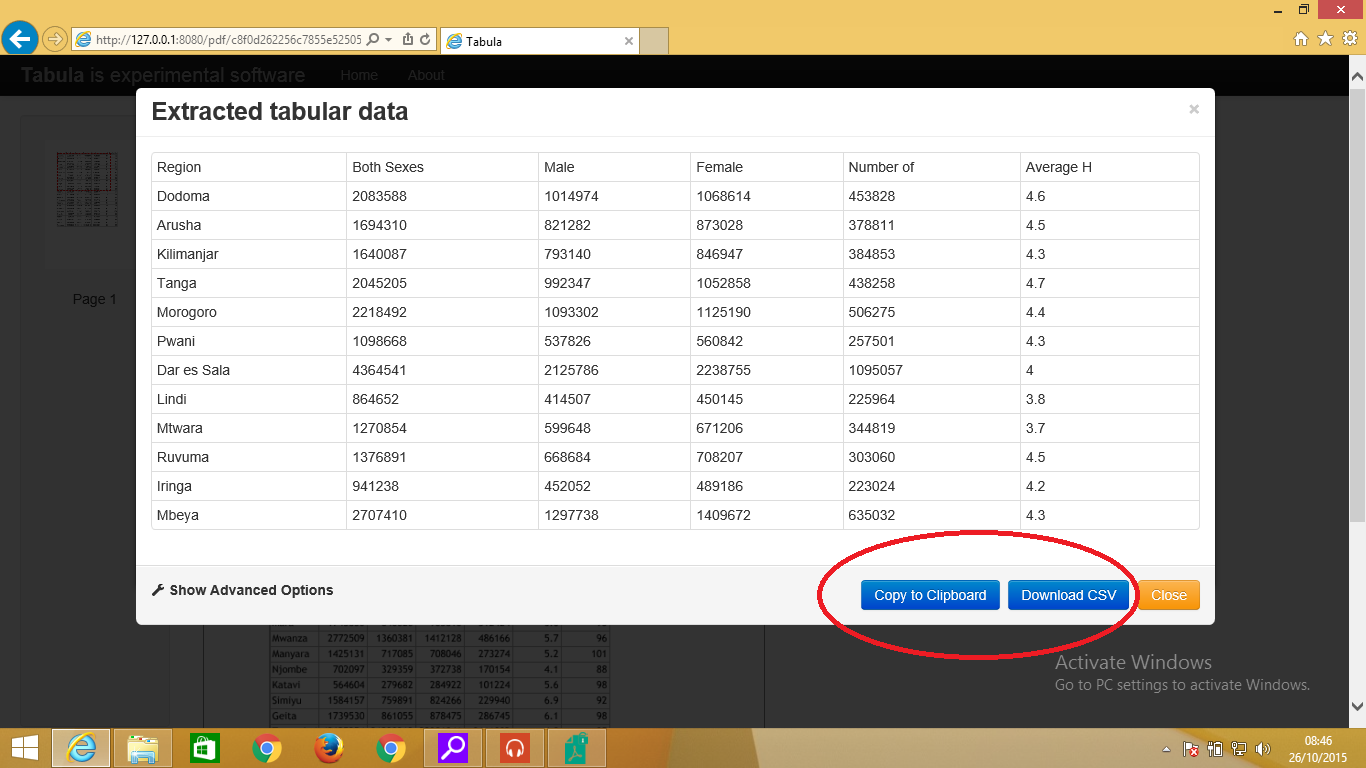
Exporting your data
The limits of Tabula
As great as Tabula is, it has some shortcomings.
- It does not work on Multi-lines rows or merged cells.
- Tabula cannot detect a scanned PDF document. it only works on text-based PDF
Quickly pick one of those PDF files and see how the extraction goes. For more information, see the references below.
Tabula and command line
If you are at ease with the command line, and would like to use Tabula on a batch of similar documents, then you could use the tabula-extractor library directly. All information about this can be found here: https://github.com/tabulapdf/tabula-extractor/wiki/Using-the-command-line-tabula-extractor-tool