In this tutorial – you will learn how to turn data, laid out for human consumption into something suitable for importing into a database such as OpenSpending and to make in computer-friendly for in-depth analysis.
You will need to download this sample data to start.
Before beginning the tutorial – open this file in a spreadsheet programme – do you see how it is laid out with lots of white space to make it easier for humans to read? This isn’t ideal for a database, so we need to give it a structure databases can understand more easily. Do you spot anything else odd about the data?
Many problems in formatting financial data can be time-consuming to solve. Luckily, there is a very powerful tool – Open Refine (previously, Google Refine) – which can drastically speed up data cleansing. This tutorial shows you how to use the tool to clear up key issues with the data.
Getting set up
Install Refine
First step is to install Open Refine by following the instructions here:
http://code.google.com/p/google-refine/wiki/Downloads
Open Refine will be an application on your computer that will open up and run in your web browser.
Note: Many users who have Windows as an operating system run Google Refine directly from a Zip File. We strongly advise against this and would suggest extracting the application into a dedicated directory.
Create Project
Now you need to upload your data to Refine. After you start Refine, it will open a browser and present its landing page. If the page does not appear automatically, you can try to open it by accessing http://localhost:3333 in your browser (simply type this into the URL bar). On the landing page, create a project, choose files and hit ‘Next’.
Before you start editing there are a couple of changes we suggest you make to your data:
Character encoding – select either “ISO 8859-1” or ‘UTF-8” – this ensures any special characters or diacritics will be displayed correctly. Parse cell text into numbers, dates, … – we suggest de-selecting this option as it can often cause errors to occur (e.g. confusion between American and British date formats).
Tricks and Tips
Google Refine is like a spreadsheet editor built for bulk data analysis and processing. It takes a bit of getting used to and unfortunately does not share many commands with familiar programmes such as Excel, however, certain elements are very simple to use.
Getting Familiar with Facets and Filters
You will use both facets and filters very often in Refine. Try creating a text facet to understand what they do:
Click on the dropdown arrow selecting:
Header > Facet > Text Facet
You will see a box appear which groups all identical cell contents and provides a count for the number of times they appear in that column in your dataset. This is useful for several reasons:
-
Spotting typos – for example, creating a text facet gives you an overview of all the unique cells in a column. This means you can easily scroll through them to review. E.g. it could show that some of your cells contain “Rroceeds from global taxes” rather than “Proceeds from global taxes” – you want to correct the former, so click edit by the facet result and edit it directly. This changes all of the cells with typos.
-
Spotting blank columns. Think a column is blank and preparing to delete it? Check quickly that there is nothing in it by performing a text facet. If the column is empty, you should get only one result (blank). You can then delete this column by clicking:
Dropdown > Edit Column > Remove this Column
Note: Facets only work up to a few thousand unique entries, so if you have a very large dataset and want to find specific values in a column with many distinct values, it may be best to use a filter to search for that item individually. Select this from the column dropdown menu as before.
Fill Down
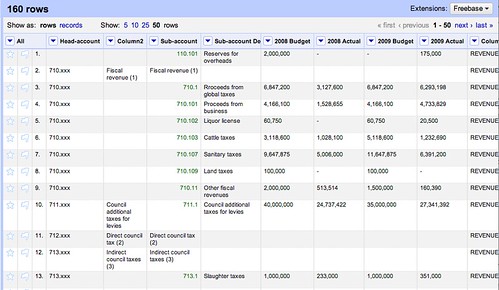
It is not uncommon for data to be produced in a way which is easy for humans to read, but not for machines. Look at the ‘Head-Account’ Column in the example below:
We can see that there is a relationship between the Head-account column and Sub-account. The head account value which is present in the second row should also ‘fill-down’ numerous rows, as all the sub-accounts fall under this category. Google Refine has a tool to copy the results of a cell down until it meets another entry, in this case, the next value for head account:
Dropdown > Edit Cells > Fill Down
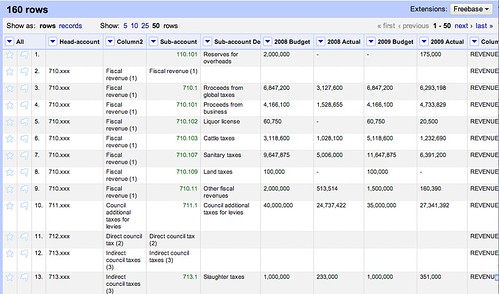
Check your results have provided the right results by performing some text facets. In this case, you will see that the cell in the top row is blank as there was nothing to fill down from, this will have to be corrected manually.
Result:
Delete Empty Columns
Use the techniques above to show a column is genuinely empty, then:
Dropdown > Edit Column > Remove this Column.
Rename Columns
Like so:
Dropdown > Edit Column > Rename this Column
Removing Pseudo Rows
You will notice that some of the rows in the data do not actually contain any data. See row 2 in the example below which contains no data for budgeted / actual amounts for either 2008 or 2009:
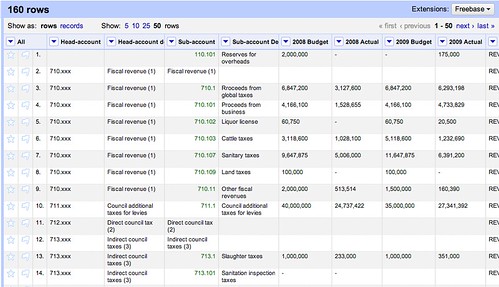
This is because it was simply a placeholder row in the original document. There are many like this in the data. To find these, we perform a text facet on the four columns 2008 Budget, 2008 Actual, 2009 Budget and 2009 Actual and in each one, select only the blank cells.
When you are done, go to the dropdown in the All column:
Dropdown > Edit rows > Remove all matching rows
Removing numbers in brackets
You will notice that in the Head Account and Sub-Account columns, a number appears after the Description. If these do not add any additional value over the head-account description, you can remove them to tidy up the appearance:
Dropdown > Edit cells > Transform
You will be taken to a screen which will ask you to input some functions in Open Refine code. You can refer to the Help section of the dialogue box for more functions and transformations, we cover just the necessary here:

Don’t worry if you don’t understand exactly what is going on here, if you are just trying to tackle exactly the same issue as here, you can simply copy the code here:
value.split("(")[0].strip()
Don’t be afraid of these commands – they are very powerful but you won’t break anything. Experiment with changing the functionality by tweaking the command – you won’t break anything, but tweaking is the best way to learn and understand how these commands work.
Transposing columns
As you will remember from the documentation on how to format your data, one row must contain one logical piece of information. As you can see from this data, we have 4 columns which correspond to time: =========== =========== =========== =========== 2008 Budget 2008 Actual 2009 Budget 2009 Actual =========== =========== =========== ===========
This is additionally complicated as each of these column headers contains multiple pieces of information – (1) budget vs actual spending and (2) which year the entry relates to. This is a key element of the data, rather than the metadata – so should actually be in the main body of the data. We need to split these elements out so that we can filter by them individually later on.
Step 1 – Transpose
Like so:
Dropdown > Transpose > Transpose Cells Across Columns into Rows
You will then be presented with a dialogue box which will look something like this:
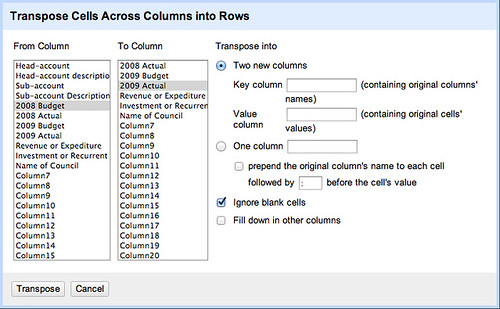
- In the From Column and To Column selectors, you need to select the range of the columns you would like to transpose (literally – flip by 90 degrees). We’re taking these four column headings and inserting
- From is the furthest column left of the range you are selecting, To is the furthest right.
- In this case you are interested in two new columns, one which will contain what were previously the contents of the header row and another to contain the contents of the cells (the amount). Put a name to describe the original column headers in the Key column field, and a name to describe the original cell contents in the Value column field.
- You should also select ‘Fill down in other columns’ to ensure that the data from the existing rows is correctly replicated down the table.
As a result, you should end up with something like this:
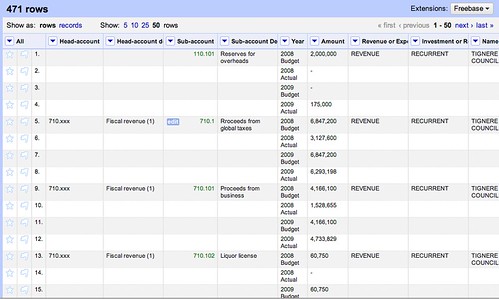
As you can see, the cells in the year column still contain information for both a) the year and b) whether the amount is budgeted or actual, so we need to split these out.
Splitting one column into multiple columns::
Dropdown > Edit column > Split into several columns
In the Dialogue box, you will be asked where the column should split, i.e. what the separator is. The column cell contents are all of the format: [YYYY][Space][Budget/Actual], so you want to simply hit the spacebar to enter that as the character you want to separate by (obviously, you can’t see that here).
You may choose to deselect ‘Guess Cell Type’ but it’s not critical here. Then hit OK.
You will end up with something which looks like this. You will need to rename the new column.
Again, it is a good idea to run a text facet over the new cells just to check that nothing has gone wrong.
Rename your columns.
Removing blank cells
As you can see – some cells still contain dashes as there is no data for that year. OpenSpending will not accept these, so they must be removed. IMPORTANT: In general – you should have a policy to distinguish between null values (absence of data) and zero values (a value that is genuinely zero) – this is very important to your calculations.
Simply filter the column for dashes:
Dropdown > Text Filter
Enter your search term. This will bring up all of the empty columns. Remove them by selecting the dropdown in the All column.
Dropdown > Edit rows > Remove all matching rows
Clear your filter ([x]) and you will see your cleaned data.
Removing commas in numbers
OpenSpending requires numbers to not have any delimiters besides a dot to designate decimals and optionally a minus sign. In many datasets, however commas or spaces are present in numbers as separators. With Open Refine, these are easy to remove. This uses an approach very similar to ‘Removing numbers in brackets’ however, where before, the command was split, here the command we run is replace.
Dropdown > Edit cells > Transform
In the input screen:
value.replace(",","")
The contents of the first double quotation marks tell the program what is being replaced, while the contents of the second tell it what to replace it with. Because we are telling it to replace with nothing (“”) – the commas are simply stripped out.
Stripping Whitespace
The final step will not show any results which are immediately visible to the human eye in Refine, however it is important to strip off any remaining spaces from the ends of cells. Here’s why:
Many databases, such as OpenSpending, group identical items and produces aggregates, so:
Fiscal revenue
and
Fiscal revenue[space]
could be perceived as different things and grouped separately. We remove the whitespace on all of the columns as a precaution:
Dropdown > Edit cells > Common transforms > Trim leading and trailing whitespace
Final fill
Once you have done this – make sure to fill down the columns so that they are all filled in!
Results
When you’ve finished, you should end up with something like this:
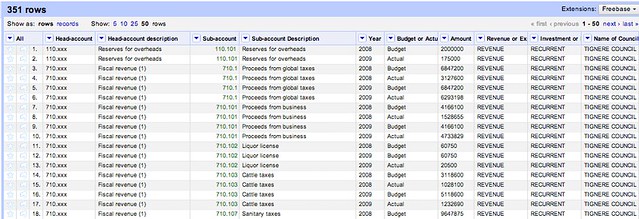
Note: You’ll notice that the first two cells in the first two columns are blank. Once you have the correct data for them, you can simply click ‘edit’ in the fields them and add the data to the fields individually.
Both datasets from start and end of this recipe can be found on the DataHub:
Last updated on Sep 02, 2013.