If you are using Google Chrome there is a browser extension for scraping web pages. It’s called “Scraper” and it is easy to use. It will help you scrape a website’s content and upload the results to google docs.
Walkthrough: Scraping a website with the Scraper extension
-
Open Google Chrome and click on Chrome Web Store
-
Search for “Scraper” in extensions
-
The first search result is the “Scraper” extension
-
Click the add to chrome button.
-
Now let’s go back to the listing of UK MPs
-
Now mark the entry for one MP

-
Right click and select “scrape similar…”
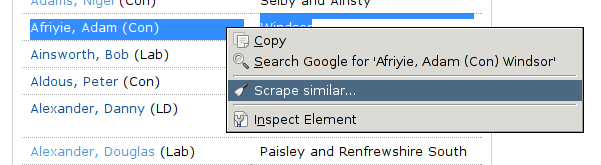
-
A new window will appear – the scraper console
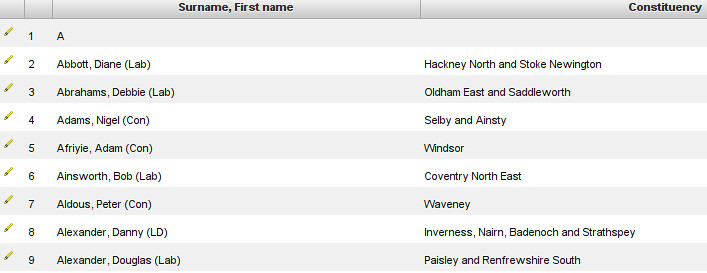
-
In the scraper console you will see the scraped content
-
Click on “Save to Google Docs…” to save the scraped content as a Google Spreadsheet.
Walkthrough: extended scraping with the Scraper extension
Note: Before beginning this recipe – you may find it useful to understand a bit about HTML. Read our HTML primer.
Easy wasn’t it? Now let’s do something a little more complicated. Let’s say we’re interested in the roles a specific actress played. The source for all kinds of data on this is the IMDB (You can also search on sites like DBpedia or Freebase for this kinds of information; however, we’ll stick to IMDB to show the principle)
-
Let’s say we’re interested in creating a timeline with all the movies the Italian actress Asia Argento ever starred; where do we start?
-
The IMDB has a quite comprehensive archive of actors. Asia Argento’s site is: http://www.imdb.com/name/nm0000782/
-
If you open the page you’ll see all the roles she ever played, together with a title and the year – let’s scrape this information
-
Try to scrape it like we did above
-
You’ll see the list comes out garbled – this is because the list here is structured quite differently.
-
Go to the scraper console. Notice the small box on the upper left, saying XPath?
-
XPath is a query language for HTML and XML.
-
XPath can help you find the elements in the page you’re interested in – all you need to do is find the right element and then write the xpath for it.
-
Now let’s assemble our table.
-
You’ll see that our current Xpath – the one including the whole information is “//div[3]/div[3]/div[2]/div”
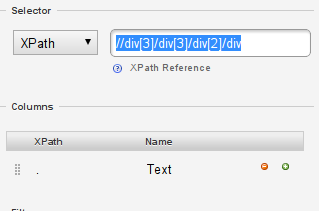
-
Xpath is very simple it tells the computer to look at the HTML document and select <div> element number 3, then in this the third one, the second one and then all <div> elements (which if you count down our list, results in exactly where you are right now.
-
However, we’d like to have the data separated out.
-
To do this use the columns part of the scraper console…
-
Let’s find our title first – look at the title using Inspect Element
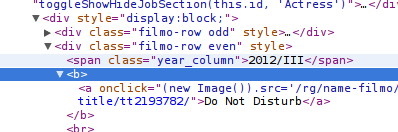
-
See how the title is within a <b> tag? Let’s add the tag to our xpath.
-
The expression seems to work well: let’s make this our first column
-
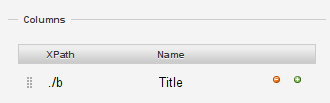
In the “Columns” section, change the name of the first column to “title”
-
Now let’s add the XPATH for the title to it
-
The xpaths in the columns section are relative, that means “./b” will select the <b> element
-
add “./b” to the xpath for the title column and click “scrape”
-
See how you only get titles?
-
Now let’s continue for year? Years are within one <span>
-
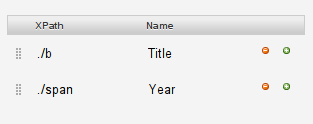
Create a new column by clicking on the small plus next to your “title” column
-
Now create the “year” column with xpath “./span”
-
Click on scrape and see how the year is added
-
See how easily we got information out of a less structured webpage?
Last updated on Sep 02, 2013.