Made to Measure: Reshaping Horsemeat Import/Export Data to Fit a Sankey Diagram
As the food labeling and substituted horsemeat saga extends across the EU, we might expect to see more and more data relating to the story turning up. One place that can almost always be guaranteed to post a few related datasets is the Guardian Datastore, who used EU horse import/export data to produce interactive map of the European trade in horsemeat.
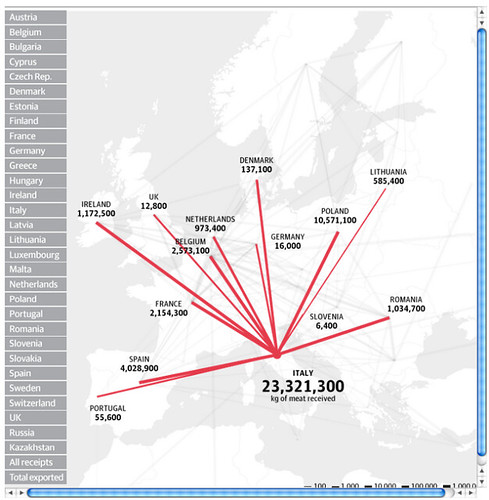
(The article describes the source of the data as the Eurpoean Union Unistat statistics website, although there’s no obvious way of recreating the Guardian spreadsheet from that source. When I asked Simon Rogers how he’d come by the data, he suggested putting questions into the Eurostat press office;-)
The data published by the Guardian datastore is a matrix showing the number of horse imports/exports between EU member countries (as well as major traders outside the EU) in 2012:
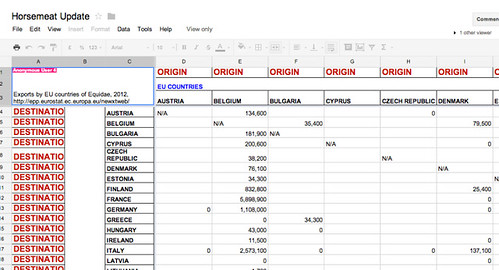
One way of viewing this data structure is as an edge weighted adjacency matrix that describes a graph (a network) in which the member countries are nodes and the cells in the matrix define edge weights between country nodes. The weighted edges are also directed, signifying the flow of animals from one country to another.
Thinking about trade as flow suggests a variety of different visualisation types that build on the metaphor of flow, such as a Sankey diagram. In a Sankey diagram, edges of different thicknesses connect different nodes, with the edge thickness dependent on the amount of “stuff” flowing through that connection. (The Guardan map above also uses edge thickness to identify trade volumes.) Here’s an example of a Sankey diagram I created around the horse export data:
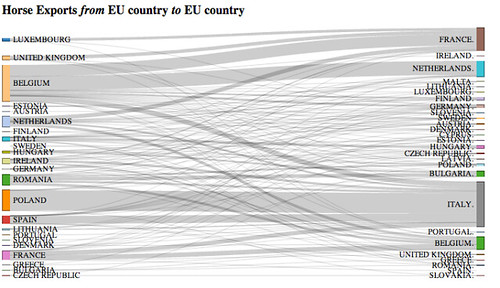
(The layout is a little rough and ready – I was more interested in finding a recipe for creating the base graphic – sans design tweaks;-) – from the data as supplied.)
How did we get to the diagram from the data?
As already mentioned, the data came supplied as an adjacency matrix. The Sankey diagram depicted above was generated by passing data in an appropriate form to the Sankey diagram plugin to Mike Bostock’s d3.js graphics library. The plugin requires data in a JSON data format that describes a graph. Getting the data into the appropriate format by hand can be a little fiddly, but there are tools available that can export the data in the correct format. One such tool is the Python networkx library which provides a set of tools for working with network data using the Python programming language. This library can be used to construct a network by defining a set of “nodes” along with the “edges” that connect them. In this case, the nodes correspond to importing or exporting countries and the edges are the number of horses exported from one EU country to another EU country in 2012. In addition, the library can generate an appropriate data object from a graph modeled using networkx. This in turn means that if you can generate a graph in networkx, you can also create a basic Sankey diagram “for free” – networkx turns the graph into JSON data, and the d3js plugin turns the JSON data into a Sankey diagram.
How can we create a model of graph from the data using networkx?
The networkx documentation describes a method – read_weighted_edgelist – for reading in a weighted adjacency matrix from a text file, and creating a network from it. If we used this to read the data in, we would get a directed network with edges going into and out of country nodes showing the number of imports and exports. However, the way the Sankey diagram above is constructed uses distinct “import to” and “export from” nodes so that exports can be seen to flow across the diagram. If you look at the diagram, a natural representation for describing the data suggests itself: transform the two-dimensional adjacency matrix into a weighted edge list in which each row has three columns: exporting country, importing country, amount.
How can a lots-of-columns matrix contain the same information as a three column list?
One way is to use R. Cutting and pasting the export data of interest from the spreadsheet and into a text file (adding in the missing first column header as we do so) gives a source data file that looks something like this:

In contrast, the edge list looks something like this:
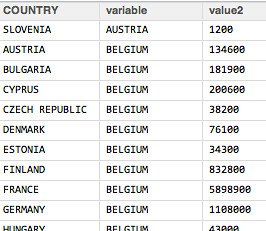
How do we get from one to the other?
The following R script can be used to achieve this transformation in just a handful of steps – it reads the file in, does a bit of fiddling to remove commas from the numbers and turn the result into integer based numbers, and then uses the melt function from the reshape library to generate the edge list, finally filtering out edges where there were no exports:
The following excerpt is in R code
#Load in the data
horseexportsEU <- read.delim("~/Downloads/horseexportsEU.txt")
#We need to load in library to help us reshape the data
require(reshape)
#Get a "long" edge list from the 2d data table
x=melt(horseexportsEU,id='COUNTRY')
# When is what looks like a number to us not a number?
#Turn the numbers into numbers by removing the comma, then casting to an integer
x$value2=as.integer(as.character(gsub(",", "", x$value, fixed = TRUE) ))
#More tidying...
#1) If we have an NA (null/empty) value, make it -1
x$value2[ is.na(x$value2) ] = -1
#2) Column names with countries that originally contained spaces uses dots in place of spaces. Undo that.
x$variable=gsub(".", " ", x$variable, fixed = TRUE)
#I want to export a subset of the data
xt=subset(x,value2>0,select=c('COUNTRY','variable','value2'))
#Generate a text file containing the edge list
write.table(xt, file="foo.csv", row.names=FALSE, col.names=FALSE, sep=",")
(Another way of getting a directed, weighted edge list from an adjacency table might be to import it into networkx from the weighted adjacency matrix and then export it as weighted edge list. R also has graph libraries available, such as igraph, that can do similar things. But then, we wouldn’t have seen how to use the “melt” method to reshape the data;-)
Having got the data in a simple form, we are now in a postion to use a Python script to generate a network, and then export the required JSON representation for use by the d3js Sankey plugin:
The following excerpt is in Python code
import StringIO
import csv
#Bring in the edge list explicitly
#rawdata = '''"SLOVENIA","AUSTRIA",1200
#"AUSTRIA","BELGIUM",134600
#"BULGARIA","BELGIUM",181900
#"CYPRUS","BELGIUM",200600
#... etc
#"ITALY","UNITED KINGDOM",12800
#"POLAND","UNITED KINGDOM",129100'''
#We convert the rawdata string into a filestream
f = StringIO.StringIO(rawdata)
#..and then read it in as if it were a CSV file..
reader = csv.reader(f, delimiter=',')
def gNodeAdd(DG,nodelist,name):
node=len(nodelist)
DG.add_node(node,name=name)
#DG.add_node(node,name=name)
nodelist.append(name)
return DG,nodelist
nodelist=[]
DG = nx.DiGraph()
#Here's where we build the graph
for item in reader:
# Even though import and export countries have the same name, we create a unique version depending on whether the country is the importer or the exporter.
importTo=item[0]+'.' #Make import country name distinct by adding a dot
exportFrom=item[1]
amount=item[2]
if importTo not in nodelist:
DG,nodelist=gNodeAdd(DG,nodelist,importTo)
if exportFrom not in nodelist:
DG,nodelist=gNodeAdd(DG,nodelist,exportFrom)
DG.add_edge(nodelist.index(exportFrom),nodelist.index(importTo),value=amount)
#Get the JSON representation of the graph/network
json = json.dumps(json_graph.node_link_data(DG))
#The "json" serialisation can then be passed to a d3js containing web page...
Once the JSON object is generated, it can be handed over to d3.js. The whole script is available here: EU Horse imports Sankey Diagram.
Whilst at first glance this recipe may seem overly complex, what it does do is show how we can chain together several different tools and techniques (Google spreadsheets, R, Python, d3.js) to create a visualisation with too much effort (honestly!). Each step is actually quite simple, and with practice can be achieved quite quickly. Steps can also often be replaced with alternative solutions, for example using tools such as OpenRefine rather than R to clean and/or reshape and reformat data. The trick to producing the visualisation becomes one of decomposing the problem, trying to find a path from the format the data is in to start with, to a form in which it can be passed directly to a visualisation tool such as the d3js Sankey plugin.
PS In passing, as well as the data tables that can be searched on Eurostat, Eurostat publish a Eurostat Yearbook, which gives an overview of a wide variety of “headline statistics” and (for the most recent release at least), includes data tables relating to reported items:
Crossposted, with minor tweaks, from OUseful.info
Front page image Mike Licht, NotionsCapital.com.
![]()