Analysing UK Lobbying Data Using OpenRefine
Being able to spot when we might might be able to turn documents into datasets is a useful skill for any data journalist or watchdog to develop, In this (rather long!) practical walkthrough post, we’ll see how we can start to use OpenRefine to turn a set text based forms into data. Specifically, given a piece of text that details the benefits awarded to a political group from a set of possible lobbying interests, how can we pull out the names of some of the lobbiests involved, along with some of the financial amounts they have donated, and turn it into data we can start to work with?
For example, in a piece of text that has the form:
Lobby Group X (a not-for-profit organisation) acts as the group’s secretariat. Company A paid £3200 towards the cost of a seminar held in May 2012 and Another Company paid £1200 towards the cost of a reception held in January 2013 (registered April 2013).
how could we pull out the name of the organisation providing secretariat support, or the names of the financial benefactors, the amounts they provided and the reason for the donation? In this post, we’ll see how we can use OpenRefine to start pulling out some of this information and put it into a form we can use to start looking for connected or significant interests.
The screenshots used to illustrate this post can be found in this photo set: School of Data – Open Refine – All Party Groups
The context for this investigation is a minor political scandal that broke in the UK over the last few days (Patrick Mercer resignation puts spotlight on lobbying). In part, the event put the spotlight onto a set of political groupings known as All-Party Groups, informal cross-party or subject or topic specific interest groups made up from members of both houses of the UK parliament (see for example the list of All Party Groups).
Many All Party Groups are supported by lobby groups, or other organisations with a shared interest. Support may take the form of providing secretariat services, making financial donations to support the group’s activities, or covering the costs of associated travel and accommodation expenses. As such, there has always been the risk that the groups might play a role in lobbying scandal (for example, APPGs – the next Westminster scandal?).
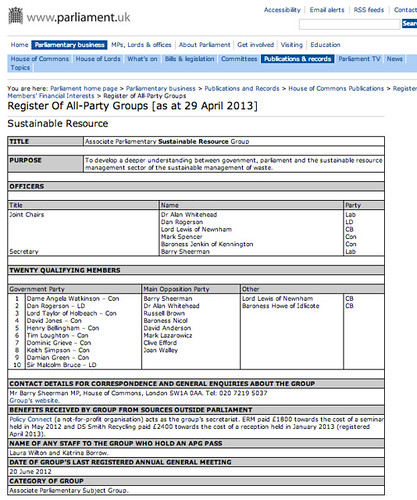
The UK Parliament website publishes transparency information that details the officers of the group and the names of twenty founding members (though the group may have many more members), along with disclosures about benefits received by the group.
The information is published as a set of web pages (one per group) as well as via a single PDF document.
A newly formed website, Allparty, has started teasing out some of this data, including trying to break out some of the benefits information and organising groups according to meaningful subject tags, although as yet there is no API (that no, no programmable way) of accessing or querying their datasets. A scraper on scraperwiki – David Jones’ All Party Groups – makes the raw data for each group available, as well as detailing group membership for each MP or Lord.
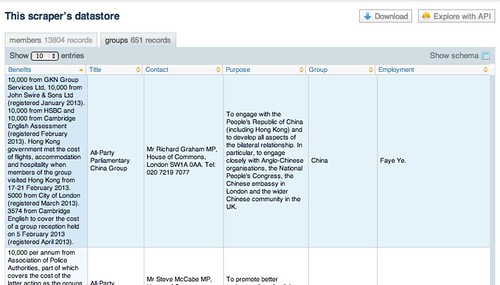
The Scraperwiki API allows us to interrogate this data using structured queries of the described in the School of Data post Asking Questions of Data – Some Simple One-Liners. However, it does not break down the benefits information into a more structured form.
So how might we start to pull this data out? From the download link on the Scraperwiki scraper, we can get a link to a CSV file containing the data about the All Party Groups. We can use this link as a data source for a new OpenRefine project:
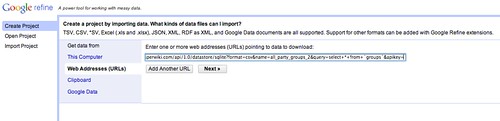
If the CSV format isn’t detected automatically, we can configure the import directly before we create the project.
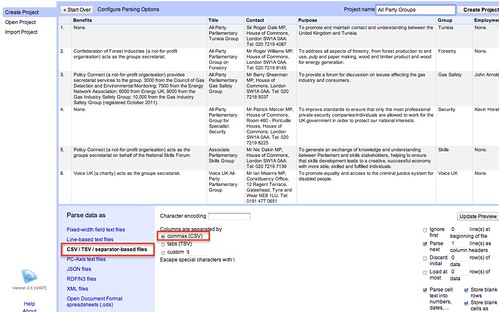
Having got the data in, let’s start by trying to identify the groups that provide secretariat support. If we don’t get them all, it doesn’t matter so much for now. The aim is to get enough data to let us start looking for patterns.
We can see which rows have a benefit relating to secretariat support by filtering the Benefits column.
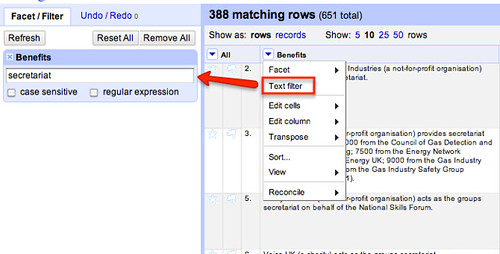
If we look at some of the descriptions, we see there is a whole host of variations on theme…

So how might we go about creating a column that contains the name of the organisation providing secretariat support?
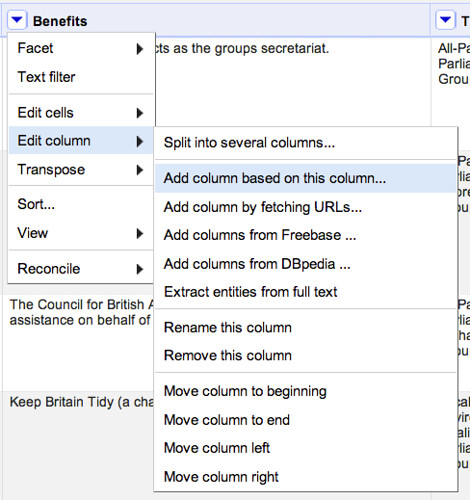
“Parsing” Data using GREL Replace Expressions
When it comes to defining the contents of the new column, we might notice that the Benefits descriptions often start with the name of the organisation providing secretariat services. We could use the GREL expression language to simplify the text by spotting certain key phrases and then deleting content from there on. For example, in the sentence:
Confederation of Forest Industries (a not-for-profit organisation) acts as the groups secretariat.
we could just delete ” acts as the groups secretariat.”. The GREL expression value.replace(/ acts as the groups secretariat./,'') replaces the specified phrase with nothing (that is, an empty string). (Note that the “.” represents any single character, not just a full stop.) By recognising patterns in the way Benefits paragraphs are structured, we can start to come up with a crude way of parsing out who provides the secretariat.
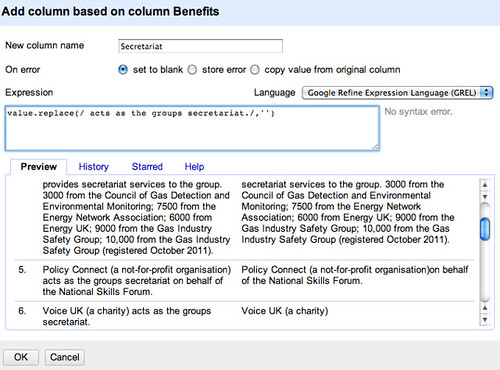
This leaves us with a bit of a mess if there is text following the deleted phrase, so we can instead delete any number of characters (.) following the phrase using value.replace(/ acts as the groups secretariat./,'').
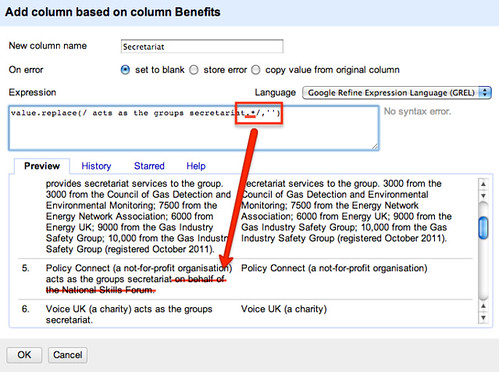
We also notice that there are other constructions that we need to account for… We can start to knock these out in a similar way by adding additional replace elements, as this construction shows:
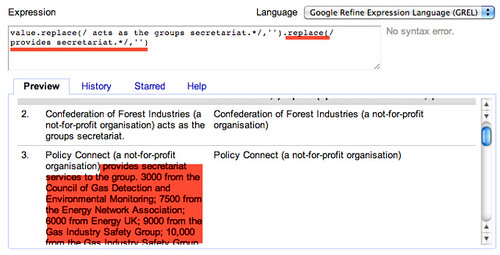
That is, value.replace(/ act as the groups secretariat./,'').replace(/ provides secretariat./,'')
If we look through some of the paragraphs that aren’t tidied up, we notice in some cases there are constructions that are almost, but don’t quite, match constructions we have already handled. For example, compare these two:
acts as the groups secretariat.
to act as the groups secretariat.
We can tweak the replace expression to at least identify either “act” or “acts” by telling it to look for the word “act” optionally followed by the character s (s?), that is, value.replace(/ acts? as the groups secretariat./,'').replace(/ provides secretariat./,'')
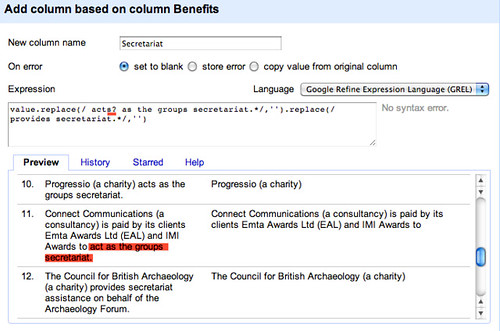
Let’s stick with this for now, and create the column, Secreatariat, looking at the unique values using a text facet. If we sort by count we see that we have already started to identify some groups that support several of the groups.
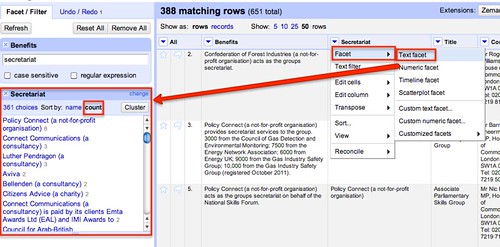
If we look through the other values, we see there is still quite a bit of work to be done.
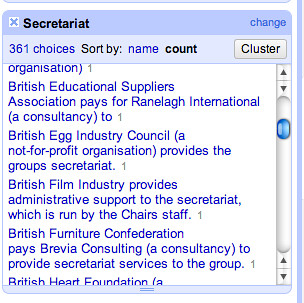
If we go back to the Benefits column and create another new column based on it, Secretariat v2, we can reuse the replace expression we started to build up previously and work on a new improved secretariat column.
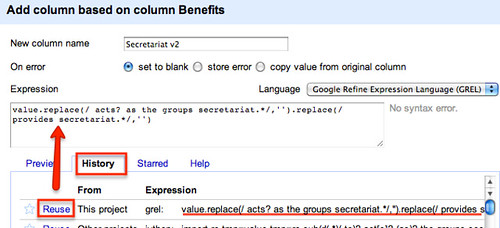
Alternatively, we can rethink our replace strategy by looking for key elements of the construction. There are various constructions based on “act” or “acts” or “provide” for example, so we can try to knock those out in a rather more aggressive way, also getting rid of any ” to” statement at the end of the phrase:
value.replace(/ act.secretariat./,'').replace(/ provide.secretariat./,'').replace(/ to/,'')
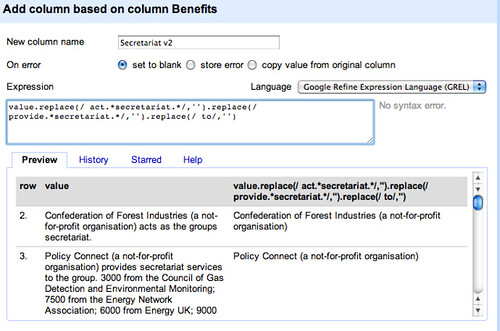
Looking through some of the phrases we are left with, there is a noticeable number of the form Company A (a consultancy) is paid by its client, Company B, to which are derived from phrases such as Company A (a consultancy) is paid by its client, Company B, to act as the groups secretariat.
We could create a second column from the Secretariat v2 column that contains this information. The first thing we’d need to do is identify who’s paying:
value.replace(/.* is paid by its clients?,? /,'')
We can tighten this up a little by splitting it into two parts to cope with the optional “its clients?” statement:
value.replace(/.* is paid by /,'').replace(/its clients?,? /,'')
The first part of this command gets rid of everything up to (.*) and including is paid by; the second part deletes its client with an optional s (s?) followed by an optional comma and then a space.
To only copy third party funders names across to the new column, we test to make sure that the replace was triggered, by testing to see if the proposed new column entry is different to the contents of the original cell, adding a further replace to tidy up any trailing commas
if(value.replace(/.* is paid by /,'').replace(/its clients?,? /,'')!=value,value.replace(/.* is paid by /,'').replace(/its clients?,? /,''),'').replace(/,$/,'')
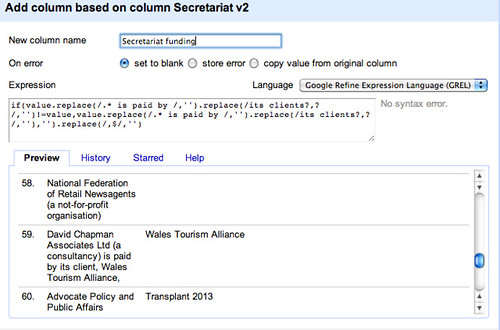
(I wonder if there is a tidier way of doing this?)
Let’s now create another column, Secretariat v3, based on Secretariat v2 that gets rid of the funders:
value.replace(/,? is paid by.*/,'')
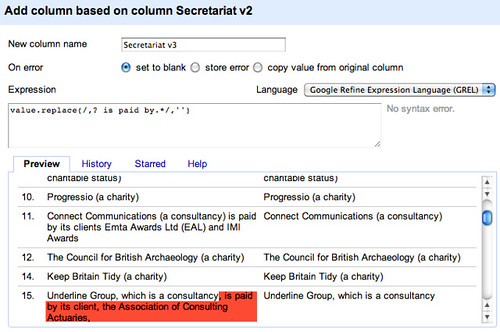
If we generate a text facet on this new column, we can display all the rows that have something set in this column:
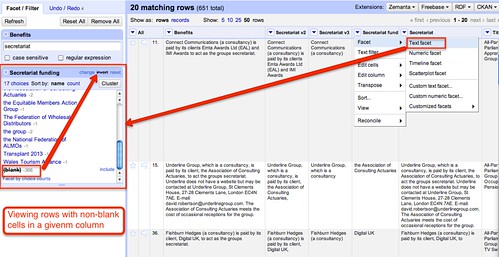
We also notice from the text facet counts that some funders appear to support multiple groups – we can inspect these directly:
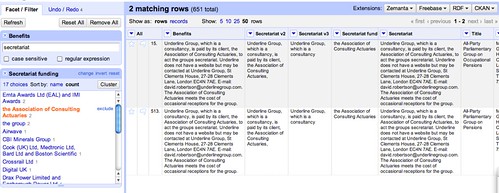
Hmm… some of the groups have similar looking names – are these the results of a name change, perhaps, leaving stale data in the original dataset – or are they really different groups? Such is the way of working with data that has now been obtained directly from a database! There’s often always more tidying to do!
If we look to see if there are any groups that appear to offer a lot of secretariat support, we notice one in particular – Policy Connect:
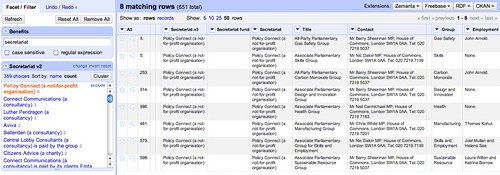
We can also see that many of the so-supported groups have Barry Sheerman as a contact, and a couple declare Nik Dakin; at least two of them employ the same person (John Arnold).
The point to make here is not so much that there may be any undue influence, just that this sort of commonality may go unnoticed when scattered across multiple documents in an effectively unstructured way.
Whilst there is still work that could be done to further tidy the data set (for example, pulling out “on behalf of” relationships as well as “paid by” relationships), we have got enough data to start asking some “opening” structured questions, such as: are there companies that provide secretariat services for more than one group (answer: Yes, though we need to check fo duplicate group names…); what companies or groups fund other parties to provide secretariat services? (Note we may only have partial data on this so far, but at least we have some to start working with, and by inspecting the data we can see how we may need to clean it further).
For example, here is a copy of a CSV file containing the data as tidied using the above recipe, and here is the OpenRefine project file. We can load the CSV file into a Google spreadsheet and start to interrogate it using the approach described in the School of Data post Asking Questions of Data – Garment Factories Data Expedition.
“Parsing” Data using Jython (Python) Regular Expressions
In the previous section we saw how we could use GREL expressions to start parsing out data from a text paragraph. In this section, we’ll see how we can use Jython (that is, Python) for a similar purpose.
To start with, here’s a quick example of how to pull out the names of groups providing secretariat services, as we did using the GREL script:
import re
tmp=value
tmp=re.sub(r'(.) ( to )?(provide|act)+[s]?.secretariat.',r'\1',tmp)
tmp=re.sub(r'(.) (is paid|on behalf of).*',r'\1',tmp)
if value==tmp:tmp=''
return tmp
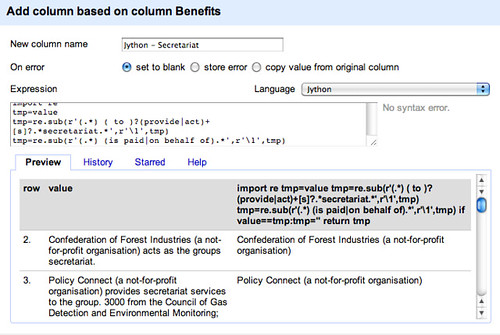
The first line (import re) loads in the required regular expression library. For convenience, we assign the contents of the cell to a tmp variable, then we look for a string that has the following structure:
- .* – any number of characters
- ( to )? – followed by a space character and optionally the word to
- (provide|act)+[s]? – followed by either the word provide or act with an optional s
- .*secretariat.* – followed by any number of characters, then the word secretariat then any number of characters.
The re.sub() function has the form re.sub( r'pattern to match',r'result of this expression',STRING_INPUT). In the script above, if the pattern is matched, tmp is set to the value of whatever is contained in the first pair of brackets of the expression being matched (\1).
We can also use regular expressions to pull out the funding groups (Python regular expressions – documentation). So for example, do the initial configuration:
import re
tmp=value
In the following expression, we take whatever matches in the third set of brackets. This broadly matches patterns of the form “X is paid by Y to provide the secretariat” and allows us to extract Y.
tmp = re.sub(r'(.) (is paid by|on behalf of)(.) to (provide|act).secretariat.',r'\3', tmp)
This results in some strings of the form: “its client, Transplant 2013,” which we can tidy as follows:
tmp = re.sub(r'its client[s,]+ (.*)[,]+$',r'\1', tmp)
There are some constructions that are not captured, eg that take the form “X provides secretariat support on behalf of Y.” The following structure grabs Y out for these cases.
tmp = re.sub(r'.secretariat.(on behalf of )([^.]).',r'\2', tmp)
If we haven’t matched any payers (so the tmp string is unchanged), return a blank
if value==tmp: tmp=''
return tmp
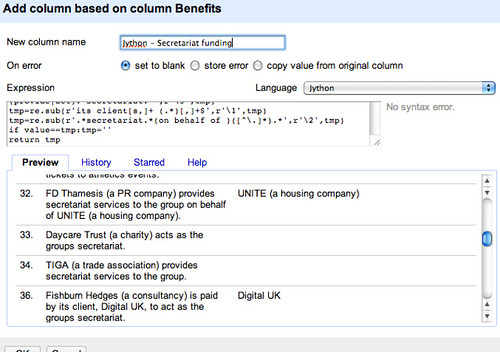
Here’s how the different techniques compare:
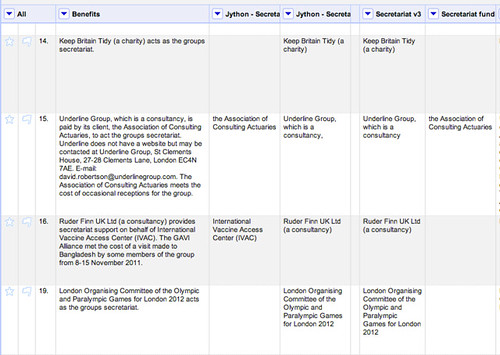
Remember that what we’re trying to do is structure the data so that we can start to run queries on it. Looking at the benefits, we notice that some groups have received financial support from different groups. For example, the All-Party Parliamentary Gas Safety Group has declared the following benefits:
Policy Connect (a not-for-profit organisation) provides secretariat services to the group. 3000 from the Council of Gas Detection and Environmental Monitoring; 7500 from the Energy Network Association; 6000 from Energy UK; 9000 from the Gas Industry Safety Group; 10,000 from the Gas Industry Safety Group (registered October 2011).
One of the things we might want to do in this case is pull out the amounts awarded as well as the organisations making the donation. Then we can start to count up the minimum benefits received (if we miss some of the data for some reason, we won’t have the total record!) as well as the organisations financially supporting each APG.
If we look at the benefits, we see they tend to be described in a common way – N,NNN from the Company X; MMMM from the Charity Y. Here’s one way we might start pulling out the data:
import re
tmp=value
m=re.findall(r'\d[,0-9]+ from the [^;.]*',tmp)
return m
*Note: it may be better to omit the the from that pattern… For example, our expression will miss “5000 from Bill & Melinda Gates Foundation (registered July 2012)”.
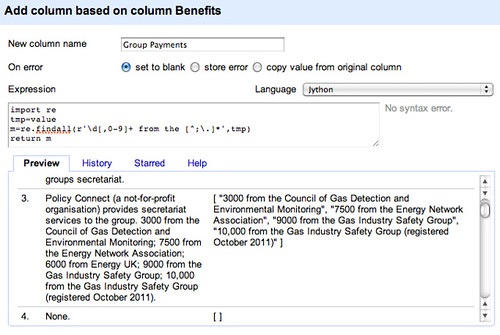
A good example to test would be the one from the All Parliamentary Group on Global Health, which also includes constructions such as 5000 from the University of Manchester and 3000 from the Lancet (registered August 2012), which the expression above will identify as a single item, and 5000 from each of the following: Imperial College, Kings Health Partners, London School of Hygiene and Tropical Medicine, Cambridge University Health Partners (registered May 2012). which (if we fix the the problem would confuse it thoroughly!
If we return the items from the list as a single string, we can then split this list across multiple rows – change the last line to return '::'.join(m):
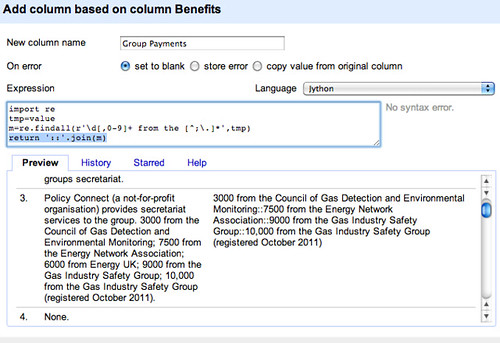
With the data in this form, we can generate multiple rows for each group, with one record per payment. Let’s join the separate items from the list using an easy to identify separator (::):
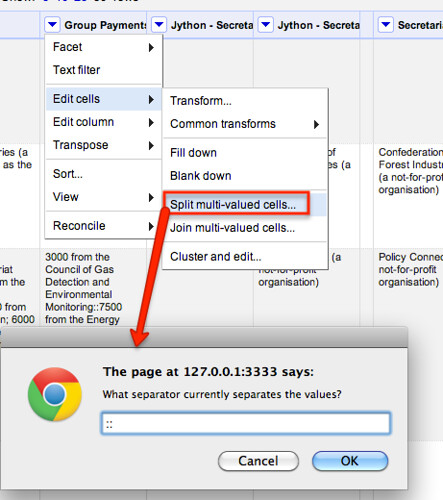
Using a similar approach to one we used before, use a text facet to only show rows with a value in the Group Payments column:
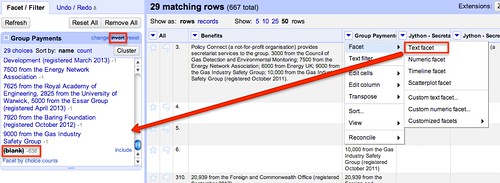
We can then fill values down on required columns to regenerate complete rows:
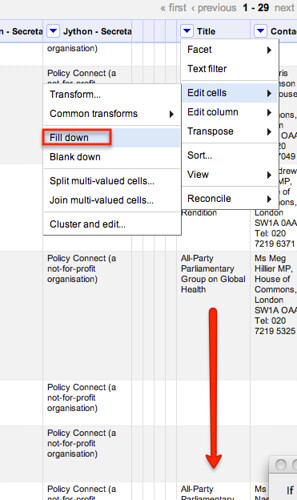
Note that if filled down the columns on the whole dataset, we would incorrectly start filling values in on rows that were not generated from splitting the payments column across multiple rows.
We can also create two new columns from the group payments column, one identifying the amount the other the name of the organisation that made the payment. Let’s go back to GREL to do this – first let’s pull out the amounts, and then remove any commas from the amount so all we’re left with is a number – value.replace(/ from the.*/,'').replace(',','')
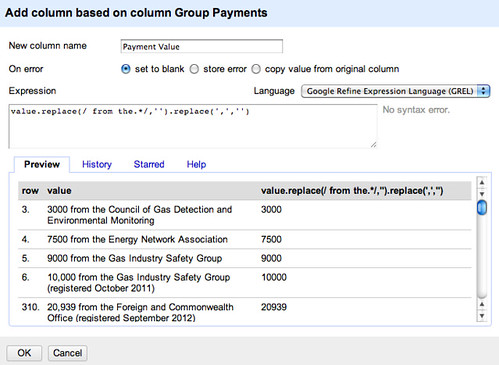
Let’s naively try to pull out the organisations responsible – value.replace(/.* from the /,'')
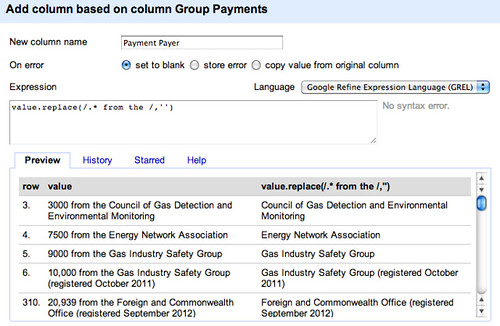
NOTE: this actually causes an error… the failure to pull out atomic statements relating to payments means that if we assume sentences are of the simple form 5000 from the Essar Group (registered April 2013) rather than the more complex 7625 from the Royal Academy of Engineering, 2825 from the University of Warwick, 5000 from the Essar Group (registered April 2013) , we end up parsing out the wrong thing.
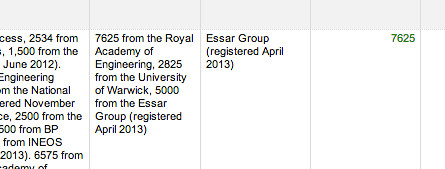
This is one of the reasons why it’s much easier of people publish data as such!
However, let’s proceed, remembering that we have broken the data, but pressing on regardless to see what we might be able to do with it if we go back and correct our errors!
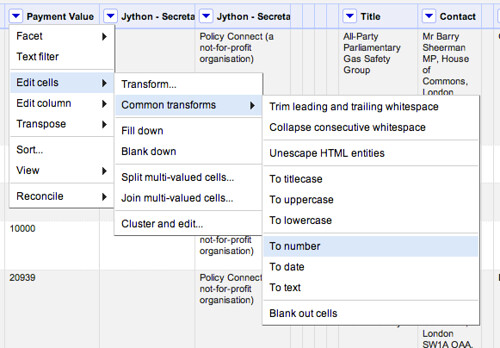
For example, let’s tidy up the data a bit more, casting the Payment Amount column to be a numeric type:
We can then use a numeric filter to identify payments within a particular range, for example (remembering that our data may be meaningless!):
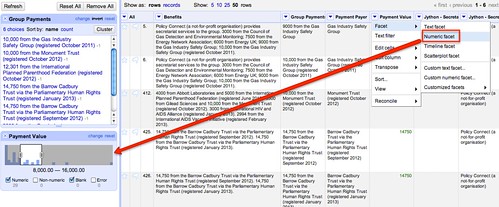
It’s also worth remembering the other problems and omissions we have introduced into this data – the the inclusion in the pattern recogniser for the amounts was over-zealous and ruled out a match on several organisations, for example; and as well as causing numerical errors, we have missed out information about separate payments that were anded together when they were declared in the same month.
The moral of this story is – look for what the exceptions might be and try to trap them out rather than letting them contaminate your data! Like I didn’t… doh!
That said, at least we’ve made a start, and can work iteratively to improve the quality of the data we have extracted – if we think it is worth spending the time doing so; we also have some data to hand that let’s us start exploring possible structured queries over the data, such as how much funding particular secretariats appear to have managed to bring in across several groups, for example, or how many benefits have been received by groups with a particular MP specified as a contact. (From the original data on Scraperwiki, we can also see which MPs or Lords are on the list of the 20 declared names for each group: do some only appear to join groups that declare benefits?!) In other words, even though we should not at this point trust any of the results of queries, because of the errors that were introduced, we can still start to explore the sorts of queries we might be able to write, which in turn can help us decide whether or not it is worth the effort cleaning the data any further…
…or maybe we should have considered what sort of data model we would be able to get out and interrogate in the first place?!
![]()