Working With Large Text Files – Finding UK Companies by Postcode or Business Area
A great way of picking up ideas for local data investigations, whether sourcing data or looking for possible story types, is to look at what other people are doing. The growing number of local datastores provide a great opportunity for seeing how other people are putting to data to work and maybe sharing your own investigative ideas back.
A couple of days ago I was having a rummage around Glasgow Open Data, which organises data set by topic, as well as linking to a few particular data stories themselves:
One of the stories in particular caught my attention, the List of Companies Registered In Glasgow, which identifies “[t]he 30,000 registered companies with a registered address in Glasgow.”
The information is extracted from Companies House. It includes the company name, number, category (private limited, partnership), registered address, industry (SIC code), status (ex: active or liquidation), incorporation date.
Along with the Glasgow information is a link to the original Companies House site (Companies House – Data Products) and a Python script for extracting the companies registered with a postcode in the Glasgow area.
It turns out that UK Companies House publishes a Free Company Data Product “containing basic company data of live companies on the register. This snapshot is provided as ZIP files containing data in CSV format and is split into multiple files for ease of downloading. … The latest snapshot will be updated within 5 working days of the previous month end.”
The data is currently provided as four compressed (zipped) CSV files, each just over 60MB in size. These unpack to CSV files of just under 400MB each, each containing approximately 850,000 rows, so a bit over three million rows in all.
Among other things, the data includes company name, company number, address (split into separate fields, including a specific postcode field), the company category (for example, “private limited company”), status (for example, whether the company is active or not), incorporation date, and up to four SIC codes.
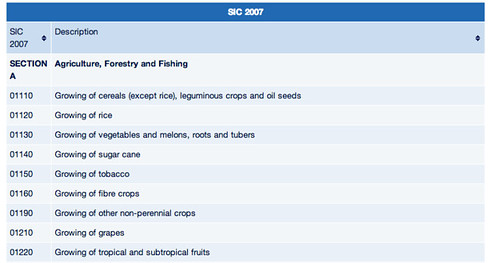
The SIC codes give a description of the business area that the company is associated with (a full list can be found at Companies House: SIC 2007).
Given that the downloadable Companies House files are quite large (perhaps too big to load into a spreadsheet or text editor), what can we do with them? One approach is to load them into a database and work with them in that environment. But we can also work with them on the command line…
If the command line is new to you, check out this tutorial. If you are on Windows, will you need to install something like Cygwin.
The command line is a place where we can run powerful commands on text files. One command in particular, grep, allows us to run through a large text file and pull out just those rows whose contents, at least in part, match a particular pattern.
So for example, if I open the command line and navigate to the folder that contains the files I want to process (for example, one of the files I downloaded and unzipped from Companies House, such as BasicCompanyData-2013-12-01-part4_4.csv), I can create a new file that contains just the rows in which the word TESCO appears:
grep TESCO BasicCompanyData-2013-12-01-part4_4.csv > tesco.csv</tt>
We read this as: search for the pattern “TESCO” in the file BasicCompanyData-2013-12-01-part4_4.csv and send each matching row (>) into the file tesco.csv.
Note that this search is quite crude: it looks for an appearance of the pattern anywhere in the line. Hence it will pull out lines that include references to things like SITESCOPE LIMITED. There are ways around this, but they get a little bit more involved…
Thinking back to the Glasgow example, they pulled out the companies associated with a particular upper postcode area (that is, by matching the first part of the postcode to upper postcode areas associated with Glasgow). Here’s a recipe for doing that from the command line.
To begin with, we need a list of upper postcode areas. Using the Isle of Wight as an example, we can look up the PO postcode areas and see that Isle of Wight postcode areas are in the range PO30 to PO41. If we create a simple text file with 12 rows and one postcode area in each row (PO30 on the first row, PO31 on the second, PO41 on the last) we can use this file (which we might call iw_postcodes.txt) as part of a more powerful search filter:
grep -F -f iw_postcodes.txt BasicCompanyData-2013-12-01-part1_4.csv >> companies_iw.txt
This says: search for patterns that are listed in a file (grep -F), in particular the file (-f) iw_postcodes.txt, that appear in BasicCompanyData-2013-12-01-part1_4.csv and append (>>) any matches to the file companies_iw.txt.
We can run the same command over the other downloaded files:
grep -F -f iw_postcodes.txt BasicCompanyData-2013-12-01-part<strong>2</strong>_4.csv >> companies_iw.txt
grep -F -f iw_postcodes.txt BasicCompanyData-2013-12-01-part<strong>3</strong>_4.csv >> companies_iw.txt
grep -F -f iw_postcodes.txt BasicCompanyData-2013-12-01-part<strong>4</strong>_4.csv >> companies_iw.txt</tt>
(If it is installed, we can alternatively use fgrep in place of grep -F.)
We should now have a file, companies_iw.txt, that contains rows in which there is a match for one of the Isle of Wight upper postcode areas.
We might now further filter this file, for example looking for companies registered in the Isle of Wight that may be involved with specialist meat or fish retailing (such as butchers or fishmongers).
How so?
Remember the SIC codes? For example:
47220 Retail sale of meat and meat products in specialised stores
47230 Retail sale of fish, crustaceans and molluscs in specialised stores
Can you work out how we might use these to identify Isle of Wight registered companies working in these areas?
grep 47220 companies_iw.txt >> iw_companies_foodies.csv
grep 47230 companies_iw.txt >> iw_companies_foodies.csv
(We use >> rather than > because we want to append the data to a file rather than creating a new file each time we run the command, which is what > would do. If the file doesn’t already exist, >> will create it.)
Note that companies may not always list the specific code you might hope that they’d use, which means this search won’t turn them up—and that as a free text search tool, grep is quite scruffy (as we saw with the TESCO example)!
Nevertheless, with just a couple of typed commands, we’ve managed to search through three million or so rows of data in a short time without the need to build a large database.
![]()