Web scraping in under 60 seconds: the magic of import.io
This post was written by Rubén Moya, School of Data fellow in Mexico, and originally posted on Escuela de Datos.
Import.io is a very powerful and easy-to-use tool for data extraction that has the aim of getting data from any website in a structured way. It is meant for non-programmers that need data (and for programmers who don’t want to overcomplicate their lives).
I almost forgot!! Apart from everything, it is also a free tool (o_O)
The purpose of this post is to teach you how to scrape a website and make a dataset and/or API in under 60 seconds. Are you ready?
It’s very simple. You just have to go to http://magic.import.io; post the URL of the site you want to scrape, and push the “GET DATA” button. Yes! It is that simple! No plugins, downloads, previous knowledge or registration are necessary. You can do this from any browser; it even works on tablets and smartphones.
For example: if we want to have a table with the information on all items related to Chewbacca on MercadoLibre (a Latin American version of eBay), we just need to go to that site and make a search – then copy and paste the link (http://listado.mercadolibre.com.mx/chewbacca) on Import.io, and push the “GET DATA” button.

You’ll notice that now you have all the information on a table, and all you need to do is remove the columns you don’t need. To do this, just place the mouse pointer on top of the column you want to delete, and an “X” will appear.
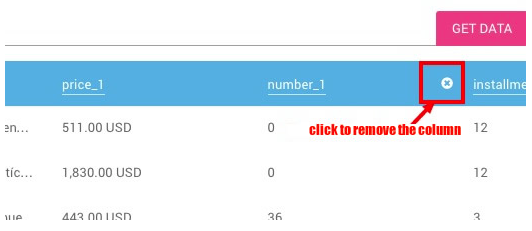
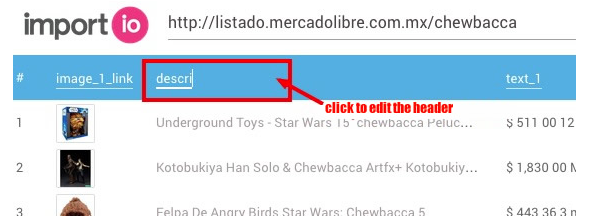
You can also rename the titles to make it easier to read; just click once on the column title.
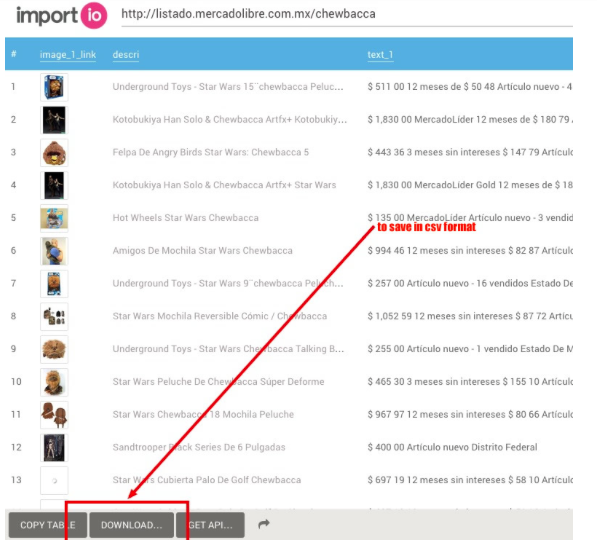
Finally, it’s enough for you to click on “download” to get it in a csv file.
Now: you’ll notice two options – “Download the current page” and “Download # pages”. This last option exists in case you need to scrape data that is spread among different results pages of the same site.
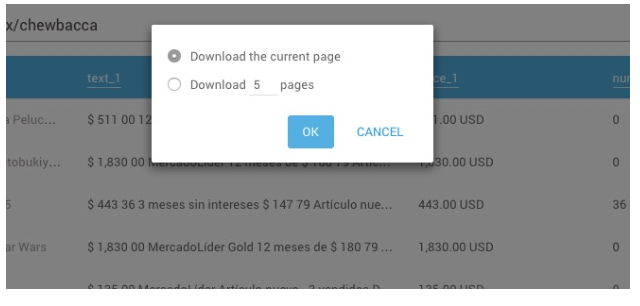
In our example, we have 373 pages with 48 articles each. So this option will be very useful for us.
Good news for those of us who are a bit more technically-oriented! There is a button that says “GET API” and this one is good to, well, generate an API that will update the data on each request. For this you need to create an account (which is also free of cost).
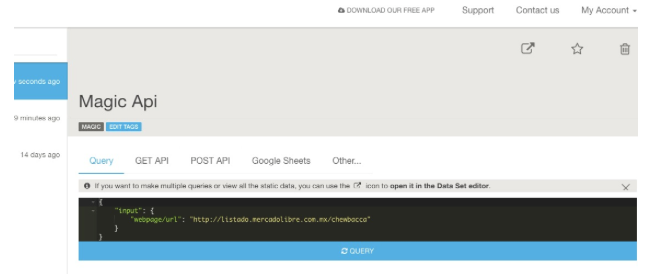
As you saw, we can scrape any website in under 60 seconds, even if it includes tons of results pages. This truly is magic, no?
For more complex things that require logins, entering subwebs, automatized searches, et cetera, there is downloadable import.io software… But I’ll explain that in a different post.
![]()