[Cross-post via Escuela de Datos: Aramís Castro, investigative journalist and general coordinator of Corresponsales.pe, a digital platform created by university students in Peru to publish information of interest for their community. The post was originally published in Spanish on Escuela de Datos. 
Corresponsales.pe uses digital tools in data journalism in its creation of news, and also trains students in public universities in digital journalism. In 2013, they won, in the Digital Press category, the most important university journalism contest in the country: Etecom 2013.]
(Texto español abajo)

As part of the global campaign for Open Data, and to support Peru’s commitment to have an Open Government, Corresponsales.pe decided to share information about the salaries of university presidents in the country. Supported by the Peruvian laws on Transparency and Access to Public Information and Sworn Declarations, we worked for four months on a digital tool that uses open data. Now, we can share more about this process.
1. Searching for the data
Despite the law on Transparency, most university websites display little information on their spending. This is why the official source of the data used in the project was the General Comptroller of the Republic, the Institution that supervises the use of public resources in Peru.
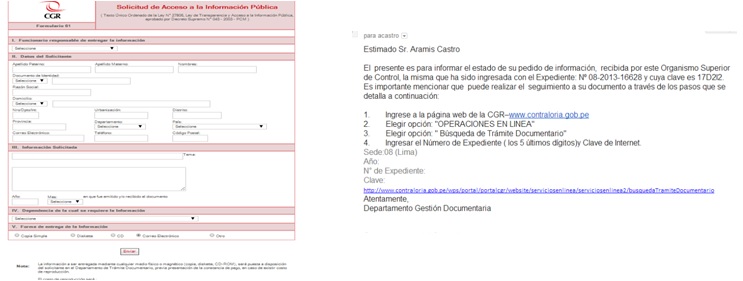
The petition for information was made through a contact form on the website of the Comptroller. We requested for the data to be sent via email.
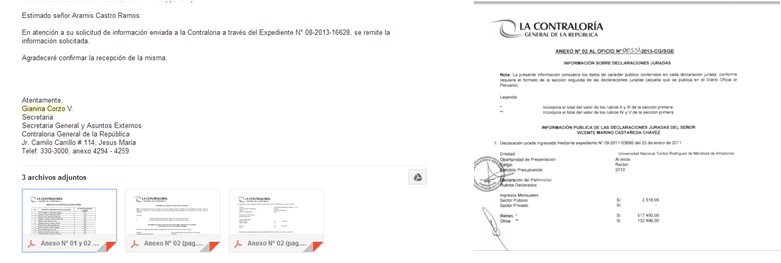
The deadline imposed by law (7 work days, and 5) expired, and no excuses were given for the delay. After almost two months of phone calls and apologies, the people responsible told us the information we requested was ready… and they sent it in a PDF. The work for Corresponsales.pe was just beginning.
2. Data analysis and processing
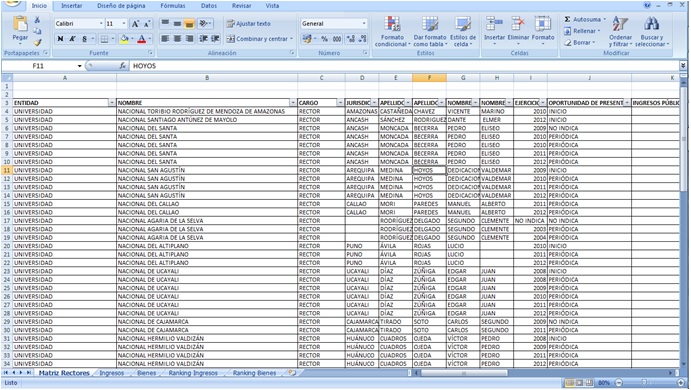
The data was comprised of around 200 pages in PDF format as digitalized images. This had to be entered manually into a spreadsheet. In order not to risk any mistakes that would compromise the credibility of the final result, this task was done one-by-one by two people (full-time) over two weeks.
The spreadsheet was verified twice by a third member of <a href=”Corresponsales.pe, again, in order to avoid mistakes.
Once this process was completed, the entire team (Corresponsales.pe journalists, designer and web developer) gathered to decide how this information would be presented. Once this stage was completed we were a bit closer to the final result.
3. Visualization and coding
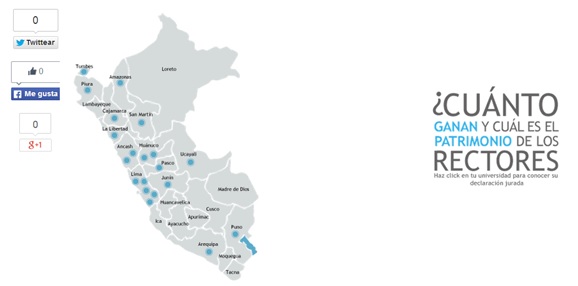
For the data visualization, we opted for a map of Peru that would interactively show all universities by region. The displayed information included the sworn declaration in PDF, the CV of the university president, and a graphic that showed the evolution of his or her income (see the image below).
Alongside the graphic design, we worked on the coding of the website. We decided against using Flash or formats that slowed down the website. Many regions in Peru don’t have reliable Internet access, and we wanted the site to work 100% for a wide audience. This is why we opted for static images.

4. Awareness-raising
Once we had a product, we reached out to regional media and to students from different universities, asking them to check out the tool and share it in their networks.
Main obstacles
- The delay in governmental response to our request.
- Receiving information in images in PDF, which didn’t allow us to use scraping programs.
- Not all university presidents in Peru turn in their sworn declarations, and not all universities publish information in this regard.
Open data
The spreadsheet we created was published in the same website as our interactive map so that all readers can analyze and look at all the information in one file.
First findings
- Between 2008 and 2012, twelve university presidents raised their income and assets.
- In 2011, for example, Dr. Pedro Cotillo became the president of the University of San Marcos. At the beginning of his mandate, he declared S/. 202 000; in 2012, he reduced his monthly earnings from S/. 15 600 to S/. 7637,32, while his assets went up to S/. 454,6 thousand.
More information
- You can find out how much university presidents in Peru earn, and how big their estate is (in Spanish)
- Take a look at the sworn declarations of university presidents in Peru (in Spanish)
[Este blog post fue escrito por Aramís Castro, periodista de investigación y coordinador general de Corresponsales.pe, plataforma digital creada por universitarios que publica información de interés y utilidad para la comunidad universitaria peruana.

Corresponsales.pe usa herramientas digitales aplicadas al periodismo de datos para la elaboración de sus noticias y, además, brinda capacitaciones de periodismo digital a estudiantes de universidades públicas del Perú. En 2013, ganó, en la categoría Prensa Digital, el más importante concurso de proyectos periodísticos universitarios: Etecom 2013.]
En el marco de la campaña mundial por los Datos Abiertos y el compromiso del Perú por un Gobierno Abierto; y con el objetivo de compartir a la comunidad universitaria los ingresos de sus máximas autoridades, apoyados en la Ley de Transparencia y Acceso a la Información Pública y la Ley de Declaraciones Juradas, Corresponsales.pe trabajó cerca de cuatro meses en una herramienta digital alimentada con datos oficiales. Aquí contamos el proceso:
1. Búsqueda y obtención de la data
Ante la falta de información –pese a estar normado en la Ley de Transparencia– en los portales de las universidades públicas, la fuente oficial para la recolección de la información fue la Contraloría General de la República, institución que supervisa los bienes y recursos públicos del Perú.
El pedido se realizó en la web de la Contraloría a través de un formulario de libre acceso al ciudadano. Incluso se detalló que la entrega sea por correo electrónico.
El plazo máximo de respuesta por Ley (7 días hábiles y 5 de prórroga de ser notificado a quien solicita la información) venció y no hubo un pronunciamiento oficial por la demora. Luego de casi dos meses de llamadas y disculpas, la Contraloría informó que tenía listo el pedido y lo enviaron en formato PDF. El trabajo para Corresponsales.pe recién empezaba.
2. Procesamiento y análisis de la data
La data –cerca de 200 páginas en PDF- al estar digitalizada como imagen y para evitar errores que comprometan la credibilidad del trabajo final, tuvo que ser ingresada manualmente (dato por dato) en una hoja de cálculo. Participaron dos personas y finalizaron la labor en dos semanas a tiempo completo.
La hoja de cálculo recibió la verificación, en dos oportunidades, de un tercer miembro de Corresponsales.pe a fin de evitar algún dato equivocado.
Tras recibir la aprobación definitiva, se definió entre todos cómo se presentaría la información. Participaron los periodistas, la diseñadora y el desarrollador web de Corresponsales.pe. Una nueva etapa concluida y cada vez más cerca la presentación final.
3. Visualización y programación
Para la etapa de visualización se optó por un mapa del Perú que mostrara la región de la universidad y que fuera a la vez interactivo. La información incluyó la declaración jurada en PDF, el CV del rector y un gráfico que mostraba la evolución en sus ingresos (ver imagen).
A la par del diseño, se trabajó la programación. Se decidió no usar flash o algún formato que retrase la carga en la web debido a que varias regiones del Perú no cuentan con buena conexión de Internet y se corría el peligro que la herramienta no funcionara al 100%. Así, se usaron imágenes estáticas.
4. Difusión
Se contactó a medios regionales y representantes estudiantiles de diferentes universidades para que conocieran la herramienta y pudieran compartirla entre sus redes.
Principales obstáculos
- Retraso en la entrega de la información.
- Información en formato PDF como imagen lo que imposibilitó el uso de programas de extracción de datos para un procesamiento más sencillo.
- No todos los rectores presentan sus declaraciones juradas y las universidades no brindan información al respecto.
Datos abiertos
La hoja de cálculo se puso a disposición de los lectores para que analicen y conozcan la información completa en un solo archivo.
Primeros hallazgos
Entre el 2008 y 2012, doce rectores del país aumentaron sus ingresos y su patrimonio, según un análisis de sus declaraciones juradas.
En 2011, por ejemplo, el Dr. Pedro Cotillo asumió el rectorado de la Universidad de San Marcos. Al inicio de su gestión declaró S/. 202 mil por concepto de bienes y otros; en 2012 redujo sus ingresos mensuales del sector público de S/. 15 600 a S/. 7637,32, mientras que sus bienes y otros ascendieron a S/. 454, 6 mil.
Más información:
- Entérate cuánto gana tu rector y a cuánto asciende su patrimonio (nota informativa)
- Conoce las declaraciones juradas de los rectores de las universidades del país (herramienta)

 After a few words from the President of Costa Rica and other government representatives, a series of talks and roundtables began… And then, in parallel, Antonio (School of Data fellow in Peru) and I started a datathon.
After a few words from the President of Costa Rica and other government representatives, a series of talks and roundtables began… And then, in parallel, Antonio (School of Data fellow in Peru) and I started a datathon. Teams were already working on their analysis at 9 sharp the following morning, while OGP San Jose sessions were taking place. The datathon participants looked for more data, did cross-comparisons, scraping, etc. By noon, they had found results and answers – it was time to start working to present them in visualizations, infographics, maps, articles, etc. At 3PM, the teams impressed us with their presentations, and showed us the following outcomes: http://ogpcr.hackdash.org
Teams were already working on their analysis at 9 sharp the following morning, while OGP San Jose sessions were taking place. The datathon participants looked for more data, did cross-comparisons, scraping, etc. By noon, they had found results and answers – it was time to start working to present them in visualizations, infographics, maps, articles, etc. At 3PM, the teams impressed us with their presentations, and showed us the following outcomes: http://ogpcr.hackdash.org This was the first data expedition in Costa Rica, and you can find more in the following links: https://www.facebook.com/ogpsanjose, https://twitter.com/OGPSanJose, https://www.flickr.com/photos/ogpsanjose , http://grupoincocr.com/open-data/miembros-de-grupo-inco-ganan-la-primera-expedicion-de-datos-en-costa-rica
This was the first data expedition in Costa Rica, and you can find more in the following links: https://www.facebook.com/ogpsanjose, https://twitter.com/OGPSanJose, https://www.flickr.com/photos/ogpsanjose , http://grupoincocr.com/open-data/miembros-de-grupo-inco-ganan-la-primera-expedicion-de-datos-en-costa-rica