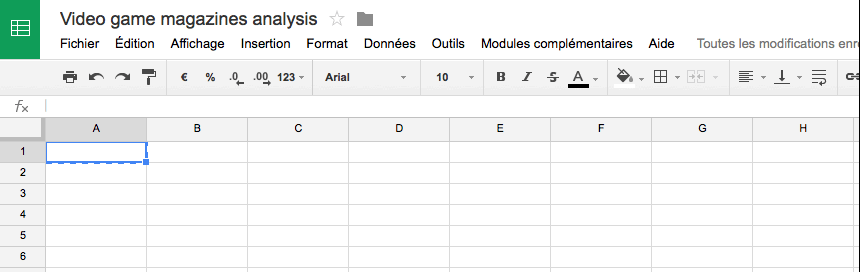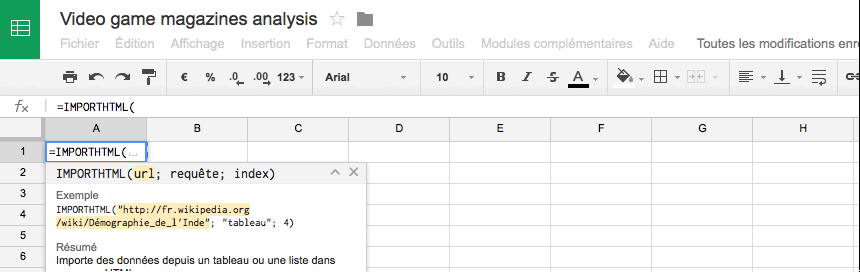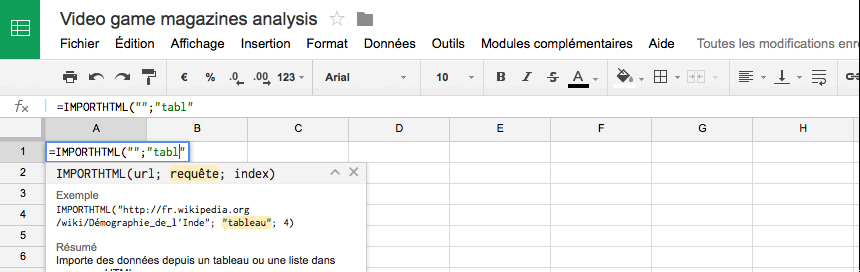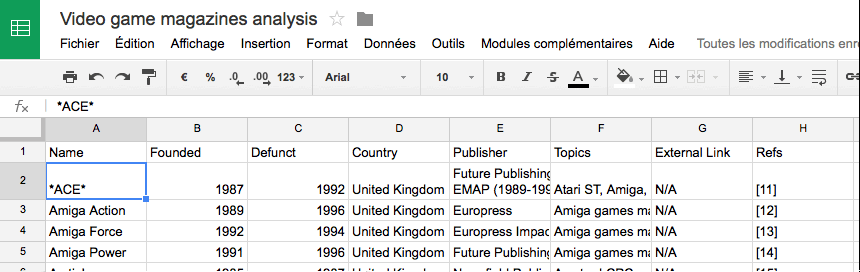
10 years of School of Data
Cédric Lombion - February 8, 2022 in Announcement, Update
10 years ago exactly, the School of Data project was announced on the Open Knowledge blog by our founder, Rufus Pollock. Over the last decade, the School of Data team and network facilitated trainings for over 6,000 individuals around the world, designed innovative training resources and methodologies and influences several dozens of organisations around the world which are now using our open resources; and we aren’t done yet!
At the time of its launch, School of Data was inspired by the model of the Peer to Peer University (P2PU; specifically the School of Webcraft, a defunct partnership between P2PU and Mozilla), but with a focus on more curated content. The project was also rooted in the Open Educational Resource movement, to which OKF contributed through its Open Education Working Group. School of Data was a product of its time: 12 days after our announcement Udacity started offering online courses and was followed three months later by edX. As the New York Times said at the time, it was “The Year of the MOOC”.
But the project – sustained in its early years thanks to funding from Shuttleworth, Open Society Foundation and Hewlett- quickly pivoted: it became clear that for an NGO aiming to promote open knowledge across the world, publishing learning modules and tutorials online was not enough. The people who needed data skills the most were often the ones least likely to come to our website and learn by themselves; we needed to go to them.
So we got to work. Starting with conferences, such as Mozfest, our team travelled around the world to teach data to journalists and civic actors. At the same time, we developed and tested the methodology and learning resources, which would become a backbone of our work: the data pipeline methodology, the data expedition format and our online learning modules. We produced several pieces of research to better understand the field of data literacy. We partnered with NGOs from other countries who shared our vision, such as SocialTIC in Mexico and Code4SA (now OpenUp). We kicked off a Fellowship programme which ran for 6 years and worked with a variety of organisations such as Hivos, NRGI, Internews, Transparency International, IREX, Publish What You Pay, IDRC, the World Bank or Code for Africa.
All this work contributed to the growth of, and was made possible by our single most important asset: the School of Data network.

The global School of Data network is visible on the map, with former Fellows as triangles, partner organisations as circles and coordination team members (current and former) as stars
Made of former Fellows and partner organisations sharing our vision and methodologies, the School of Data network was a necessary step to address one of the biggest challenges that we had identified: the lack of mentors with the data literacy skills needed to implement our vision on the field, around the world. Today the network allows the School of Data to deliver trainings in fifteen languages across the world, ensuring that our trainings are inclusive and culturally relevant.
What’s next
Those who follow the project know that the School of Data has been quiet in the past few years. Although the work never stopped, we are very much aware that our public activity fell short of the expectations that our friends and partners had come to expect from us. But this anniversary comes at a perfect time: under the leadership of our new CEO, Renata Ávila, OKF will once again invest in reimagining and launching an updated School of Data, combining knowledge, technical tools and critical thinking about the present and future of technology. With this renewed focus, we will be able to support our network better, continue innovating with better training and learning resources, and, more importantly, speed up our work toward achieving our vision: a world where everyone, from civil society organisations, to journalists and citizens, are empowered with the skills they need to use data effectively, transforming into knowledge, leading to change.
If you want to work with us on what’s coming next, don’t hesitate to contact us!
![]()