Feedback from the 2016 Summer Camp – Kabu
Kabu Muhau - August 12, 2016 in Event report, Fellowship
From May 15th to 21st, 40 people from 24 countries gathered at Ibúina in Sao Paulo, Brazil, for the 2016 School of Data Summer Camp. Kabukabu Muhau, a 2016 School of Data Fellow from Zambia, shares her thoughts about the event.

SCODA 2016 Fellows. Left to right; Raisa, Danny, Ximena, Omar, Malick, Paul, Kabu, Vadym, Nika and Precious
Ola!
Yep I know one Portuguese word thanks to the School of Data summer camp held in Ibiuna Brazil! Exciting right? But don’t you dare judge me for learning only one word. There was so much happening I could barely keep up! Plus the food was amazingly delicious; my mouth was always full with it!

Omar and I getting more food ☺☺☺
Members of the community were exceptionally welcoming. I’ve never met so many people with such a passion for data! The camp brought together people with different data-literacy backgrounds and it was really awesome to learn about data from different perspectives.
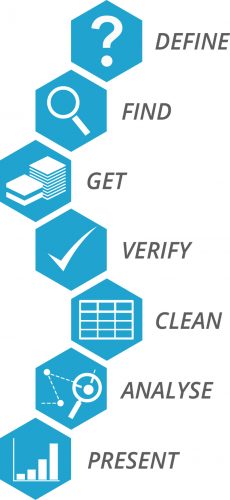
So you may ask, what did you learn? Well, my main purpose in applying for the School of Data Fellowship was to learn new data skills that could be applicable in my home country Zambia, specifically in the health sector. To better explain the skills I learnt in the various data-literacy sessions (wish I could’ve attended more!) I attended, I will use the data pipeline: A data pipeline simply shows the different processes involved in data management. There are six main stages in the data pipeline;
- The the data pipeline starts with the DEFINE step, which is the same as problem identification; it is usually the first step in research. Defining a workable research problem, usually involve three steps:
- Selecting a topic area
-
Selecting a general problem
-
Reducing the general problem to a specific, precise and well delimited problem by listing possible answers to the general problem.
-
Next comes the FIND step, wherein you have to find where the data you need is available. This involves various techniques, from using Google Search operators to identifying how the data could be collected in your environment.
-
Then comes the GET step. In this part of the pipeline, you are required to collect the data that relates to the selected/identified problem. Different methods can be used to collect data depending on the selected problem.
-
Data VERIFICATION is done after collection, to prove whether the data collected is valid or not
-
CLEANING is done to remove inconsistencies in the data
-
Data ANALYSIS is a process of evaluating the data and converting it to something more meaningful that could be used for decision making.
-
PRESENTATION is the final stage in the data pipeline, where the analysed data is displayed by use of maps, graphs or tables or any other means.
Various knowledge exchange sessions were held throughout the camp, which allowed me to learn many amazing skills that I will use through my fellowship and beyond:
“How to sell”, by Nika, another School of Data fellow from Latvia, was a sessions about the skills required towas a sessions about the skills required to sell a project idea to potential partners. It mainly focuses on four key points; NEED, FACT, ATTRIBUTE and BENEFIT.
- Needs: talk about what has to be addressed
-
Fact: give evidence of similar projects you have done in the past and any results yielded
-
Attribute: mention any qualifications that you hold
-
Benefit: simply mention what the person or organisation will gain from partnering with you.
Yuandra Ismiraldi, a 2014 School of Data Fellow from Indonesia, Ismiraldi, a 2014 School of Data Fellow from Indonesia, and Malick Lingani, a 2016 School of Data Fellow from Burkina Faso, Lingani, a 2016 School of Data Fellow from Burkina Faso, conducted a session on how data can be collected using sensors. They explained how sensors can be used to measure the PH of water to determine its quality; and also measure temperature and humidity for weather forecast. The information collected from sensors is temporarily stored in a SIM card via a GPRSbee, a SIM card socket which allows the use of SIM cards as a temporary storage solution. The geocoded information is then sent to a central server at defined time intervals (every minute, hourly, daily).
I also also learnt about about a very important data cleaning tool called OpenRefine, which can be used to highlight inconsistencies in the dataset, then go on to clean them. It is so easy to use and I’ve already started practicing cleaning datasets with it. I think it is much better tool for data cleaning than the Excel I am used to.
Finally, while Finally, while I usually use SPSS for data analysis,, II was introduced to the statistics software the statistics software R at the camp and will soon be exploring how it works! Tableau is a data visualisation is a data visualisation tool I was also also introduced to and I plan to explore it it more. In addition, whenever I find myself in a situation where I need to present my data without using a computer, I will always refer the work of the work of Sylvia Fredriksson, from Ecole des données (School of Data France)Sylvia Fredriksson, from Ecole des données (School of Data France)on how to present data physically.
Silvia’s physical data presentation session
During the Summer Camp, Fellows had a specific set of sessions tailored for their need: the Fellowship track. It was run by three amazing coordinators – Camilla, Cedric and David – and itand it introduced us us to the FFellowship programme. Thankfully, they guided us patiently, making the whole programme seem manageable. It was really exciting to meet people from different countries, to learn about their cultures and what they use data for in their everyday lives. I now have a bigger data-literacy family, all thanks to Summer Camp!
Muito obrigado SCHOOL OF DATA for this awesome opportunity!!! I guess I learnt more than one Portuguese word…

We had a whole lot of fun!

SCODA African team

SCODA 2016 African fellows.

![]()