Open Election Data Week in Nepal
Prakash Neupane - December 16, 2013 in Community
The recently held Nepalese Constituent Assembly (CA) election was the object of a lot of expectations from Nepalese people. The Constituent Assembly’s previous failures have raised people’s awareness. Perhaps because of these failures, everyone from teenagers to the elderly had big expectations for the election and was observing the results every minute. Meanwhile, the most amazing thing happening was that almost all the major media (online, paper, and TV) were presenting the results in the best possible form: they were playing with data and showing nice visualizations of that data. Today, data journalism is gradually gaining prestige among journalists and the media (print media and visual media) in Nepal and among Nepalese people. For this reason, the news media are giving priority to the visualization of data. Even other organizations (non-media CSOs and international organizations) are practicing data visualization to convey their message to the general populace.
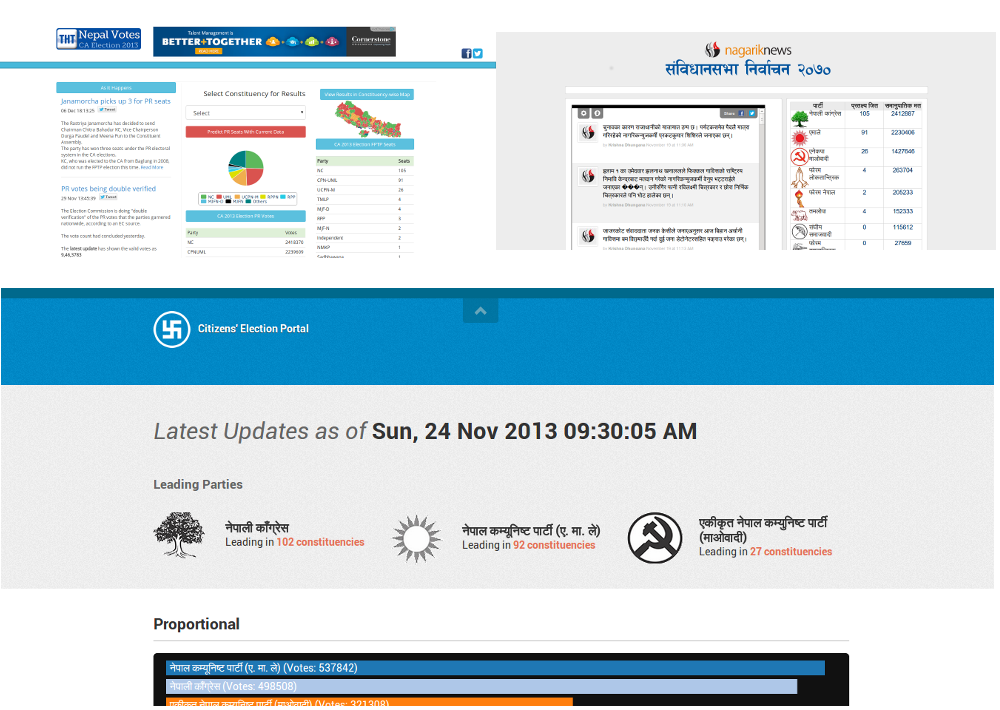
At the same time, we organized Open Election Data Week from 23rd November to 29th November. The idea of this program was to gather interested people who could make a contribution around online election data. The first task was to gather data from various sites. As the election results were not complete, most of the results seemed to be scattered, and so we needed to gather basic data from different resources. The official organization for election data is the election commission.
In the end, we achieved success success collecting different election data:
- Data about registered voters. For the first time, the Election Commission adopted a voting process that used a voting card with a photo. To do this, they started issuing voting cards few years ago. The information about the voters is not publicly available, but the number of voters for different constituencies is available.
- Data about the candidates for the election. There were around 6,149 candidates fighting for 240 positions. The data provides information about the candidates (name, age, party, symbol, …) for particular constituencies.
- Data about votes gained by each candidate in their constituencies. This means that the data covers the total details of the votes received by individuals.
- Data about invalid and valid votes. These data can tell which places have fewer people who took part in the election and also tell in which places people don’t know about voting procedures (i.e. where the government and political parties failed to train people about the voting process).
- Data about public relation votes. This will tell which party gained the highest PR votes for the CA and how many seats they gained through it.
The election data is available on GitHub.
Now that we have collected all the data properly and stored it in an open format (CSV), we can present some of the data visually:


More details are available here.
What is Next
This visualization process is not going to stop here. Our next job is to look at election spending. The government hasn’t published details of money spent in the election process. But the Election Ministry’s officials have said that they have estimated the total expenditure (of government and non-government funds) to stand at Rs 50 billion under several headings. We think it will be very interesting to show how the government undertook expenses in the election.
![]()