Hunting for Data – Learning How to Read and Write Web Addresses, aka URLs
In every data explorer’s toolbox, there is likely to be a range of tools and techniques that have proven their worth again and again. For discovering data on the web, both the public web and private, or closed, corporate intranets, being able to read a URL is one of the backpocket tools we can make use of on a daily basis.
When running web searches, being able to refine our search queries based on information we have about a website’s architecture, on the format of documents we desire to find, or simply by knowing the address of the website we are likely to find the information on, can aid the discovery process.
When writing web scrapers, programmes that literally “scrape” data from an arbitrary website so that we can work with it in our own databases, having a good knowledge of how to structure URLs, and how to spot patterns across them, can prove an invaluable source of shortcuts.
URLs – Uniform Resource Locators [W3C specification] – are perhaps more commonly known as web addresses or web locations. Whenever ever you see a web address such as schoolofdata.org or http://datajournalismhandbook.org/1.0/en/getting_data_3.html, that’s a URL.
You can find the web address for the page you are currently on by looking in the location bar or address bar at the top of your browser:
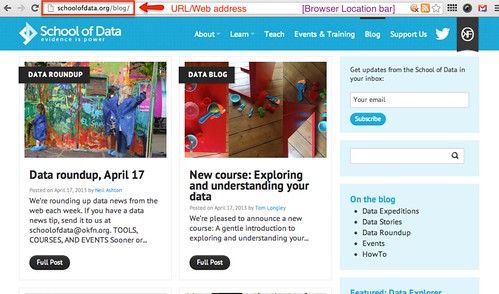
Whenever you click on a link in a web page, your browser will load the web page – that is, “go to” the web address – associated with the link. If you hover your mouse cursor over a link – such as this one – you should be able to see the web address that clicking on the link will transport you to in the bottom left corner of the browser:

In the simplest case, the contents of a web page are determined solely by what appears in the location bar. (Web servers are also capable of using other pieces of information to decide what to present in a web page, but we won’t be concerned with them in this post…)
The Anatomy of a URL
For the purposes of getting started, we can think of web addresses as comprising four parts, although only the first of them, the domain, is a must have:
- the domain, such as schoolofdata.org or www.cse.org.uk. The domain may be further broken down to the top-level domain, such as .com, .eu, or .org.uk; a registered name within that top-level domain, such as okfn or schoolofdata; and subdomain, such as www. It is worth remembering that organisation may actual register a name across several top-level domains (for example, UK companies may register their name as a .co.uk address as well as a .com address. Sometimes this different addresses are redirected so that they point to the same website, sometimes they point to different websites altogether.
- the path: path elements are like nested folders or directories on a computer and are separated by forward slashes (/). In a URL such as http://datajournalismhandbook.org/1.0/en/getting_data_3.html the path is represented by /1.0/en. Sometimes you may be able to make a guess at what path elements represent. In this, I case that 1.0 is the version of the handbook and en is the language code for English, so I’m guessing this path leads us to version 1.0 of the handbook in English.
- the page, or name of the document or resource we’re going to load. For example, getting_data_3.html is a page that can be found in the /1.0/en directory on the datajournalismhandbook.org domain.
- the variables, “arguments” or parameters: sometimes you may notice a ? in a URL, as for example in this URL for a search results page, https://schoolofdata.org/search/?q=open+data. (You might notice there is no “page” element in that web address. That’s fine. There are several situations where this may occur, such as when a “default page” (such as index.html) is presented, or when the URL is a ‘prettified” version that masks a clunkier URL on the server and from which the page is actually served.) It is not uncommon to find pages where the query is followed by a series of ampersand (&) separated argument statements, showing that several variable settings are being used to determine what to display on the page. In many cases, the order in which these are presented does not matter (although on some websites it does!)
Tinkering with URL Arguments – Custom Searches
Once you start to get a feel for how to read URLs, you can start to hack them. Let’s start with a search query, such as https://schoolofdata.org/search/?q=open+data. Click on the link, and then see if you can change the URL to produce a search for OpenRefine.
Here’s how I changed the URL: https://schoolofdata.org/search/?q=openrefine
Many websites use the q= argument to denote a search query. For example, here’s a search on the DuckDuckGo web search engine: https://duckduckgo.com/?q=data+wrangling
Sometimes, you might find there are other arguments you can change directly in the URL bar to limit a search. How might you change this URL for a search on the World Bank site to search between the start of April 2009 and the end of June 2012?
Can you see from the URL where the search term is described? Can you edit the URL to search for mortality indicator africa, without a date range?
If you look at the World Bank search page, you’ll notice that there are a series of “facets” that allow you to limit your search to a particular class of results.
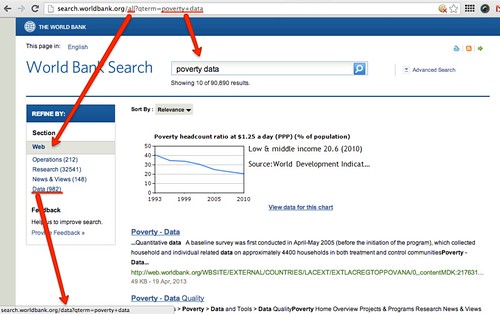
What happens to the URL if you select one of those facets, such as the data facet?
In this case, a path element, rather than the query argument, has changed.
Could you make a guess at how to change the URL to limit the search to some of the other top level facets, such as research, or operations? Try it – if it doesn’t work, you won’t break the web; and you can always click on one of the original links to see what the actual URL looks like.
Try limiting a search using the other search filter links, such as by Type or Database in the data area. Watch how the URL changes – do you think you could navigate the search options simply by hacking the URL?
On many websites, advanced search form fields tend to map on to URL arguments. If you know how to read and write a URL, you can often create advanced custom searches yourself simply by tweaking the URL.
Using URL Information to Refine Web Searches
It’s also worth noting that we can use information gleaned from reading a URL to refine a web search. For example, many web search engines support search limits (advanced search features) that let you limit the results displayed in specific ways. For example, adding the search limit:
- site:gov.uk
will limit search results to pages hosted on the .gov.uk domain. Try one. We can also use the site limit to search within a particular domain, as for example here: site:bristol.gov.uk underspend. This trick can be particularly useful searching your own organisations’s website if its own search functionality isn’t up to much!
If you notice a particular path element in a URL, you can often use that to limit a search to results that contain that path. For example, looking at the UK Drinking Water Inspectorate research report archive, I notice that reports have URLs of the form:
- http://dwi.defra.gov.uk/research/completed-research/reports/DWI70-2-206exsum.pdf
Using this as a crib, I could search for additional reports using an “in URL” limit such as inurl:research/completed-research/reports to search for documents that lay down that path.
We can also go fishing, for example for data relating to school dropouts as recorded in a spreadsheet (filetype:xls) file stored down a inurl:reports path on a site:.edu domain: filetype:xls site:.edu inurl:reports dropout.
Hacking URLs on the Off-Chance…
Whenever I see numbers in a URL, I wonder if they’re hackable. For example, consider the URL:
I guess that the 1.0 refers to the version of the handbook. If the handbook went to a second edition, it might be that the we would be able to find it via the path element 2.0. Or may ealier point releases are available (in this case, I don’t think there are…). There is also a number on the page element. Perhaps if we changed the URL to point to getting_data_2.html it would still work?
Many social media sites use user names as a URL path element. Many people or organisations try to use the same username on different websites, not only for “brand consistency” but also because it’s easier to remember. For example, the Open Knowledge Foundation often uses the username okfn. If I tell you that the following website patterns exist on different social media sites:
- flickr.com/people/USERNAME
- twitter.com/USERNAME
do you think you could find the Open Knowledge Foundation pages on those sites?
Here’s a trick that starts to get us on the way to trying to finding a few more – search Google looking for okfn in page URLs: https://www.google.co.uk/search?q=inurl:okfn
Tweaking Path Elements
In many cases, the path structure of a URL replicates the structure of a website, or part of the website. Consider this URL for a post on the School of Data blog:
Q: What happens if we remove the page component to give a URL of the form https://schoolofdata.org/2013/02/19/ ?
A: You get all the posts posted on that day.
If you know the system that is being used to publish the content, you can sometimes hack the URL further. For example, I know that the School of Data blog is hosted on WordPress, and I know that WordPress has a range of URL arguments for tweaking the display. For example, I can display the posts in the order in which they were created by adding the ?order=asc parameter to the URL: https://schoolofdata.org/2013/02/19/?order=asc
(See also: Viewing WordPress Posts in Chronological Order. WordPress also has considerable support for delivering machine readable RSS feeds of content hosted on a WordPress blog which can be obtained with a feed tweaks to a WordPress URL: WordPress Codex: Feeds.)
How would you change the URL to find posts published on the School of Data blog in November 2012?
Formatting Data Via the URL
Sometimes it may be possible to tweak URL parameters in order to obtain different output formats for a document. For example, if you have the key for a public spreadsheet on Google Docs, you should be able to work out how to create a URL that lets you obtain a copy of the file in a particular document format, such as a text based CSV (comma separated variable) file, as an Excel spreadsheet (filetype: xls) or as a PDF file.
For example, can you spot which part of the following URL specifies the output type as CSV?
Take a guess at a URL that might display an HTML (web page) version of this spreadsheet. Or a PDF version.
You can also generate these URLs from within a Google Spreadsheet, via the File/Publish menu:
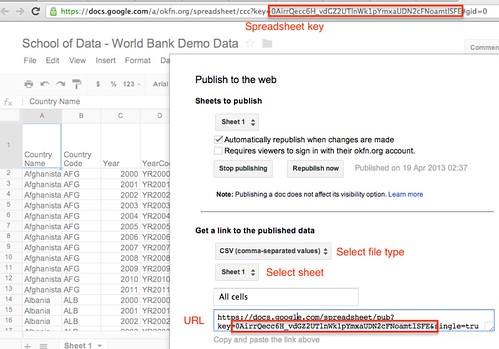
When working with Google spreadsheets, you may find some documents contain multiple sheets. Some file formats, such as CSV, only display a single sheet at a time. By inspecting the URL, can you see where the ID number for a particular sheet may be specified:
HINT: parameter names that contain id often refer to unique or global identifiers… In addition, computer folk often start counting from 0 rather than 1…
Google Spreadsheets can generate these URLs because they are constructed out of particular elements. If you learn to read and write the structure, you can start to generate these URLs yourselves. In the case of Google Spreadsheets, just by knowing the key value of the spreadsheet you can then start to generate valid URLs for different formats or views onto the spreadsheet.
Summary
In this post, you’ve seen how web addresses, or URLs, are structured, and learned how to start reading them. Hopefully, you’ve also tried rewriting a few, too, and maybe even started writing some from scratch.
If you find yourself working with a particular website a lot, it can often be useful to get a feel for how the URLs are structured in order to navigate the site in ways that may be difficult to traverse via links on the website pages themselves.
Websites published using common web platforms can often be recognised from the way their URLs are structured. If you know how to handcraft URLs for those platforms, you may be able to tweak a URL to get hold of the information in a format that is more useful to you than a traditional page view. For example, you can obtain a structured RSS version of posts on a particular topic from a WordPress blog (which can be useful for syndication or screenscraping purposes), or given just a key for a public Google Spreadsheets document, construct a URL that points to a CSV version of the second sheet of that spreadsheet.
![]()