Meet the 2016 School of Data Fellows!
Marco Túlio Pires - May 7, 2016 in Announcement, Community, Fellowship

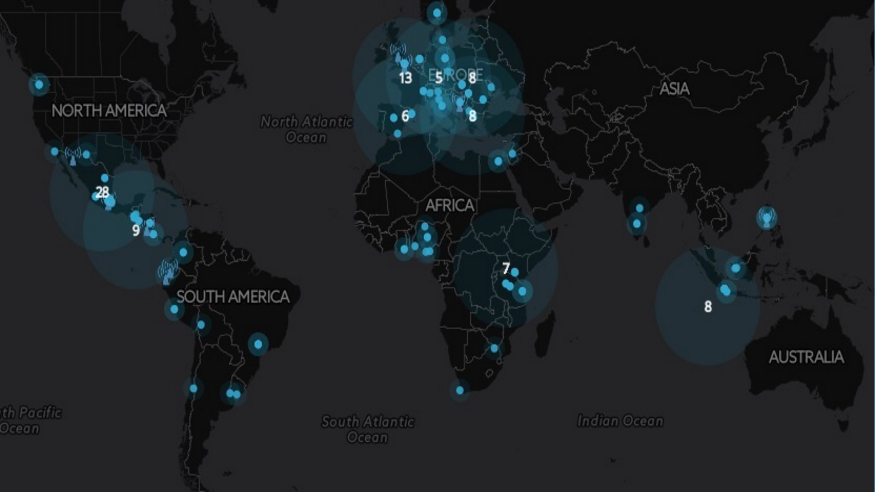
For the past three years, School of Data has been identifying and selecting outstanding data-literacy practitioners around the world. Our Fellows have led the way in bringing data-literacy knowledge and practices to their region: 26 individuals in 25 different countries in regions right across Latin America, Europe, Africa and Asia.
When we set out to revamp the Fellowship Programme in 2016, we challenged ourselves to involve other organisations that care as deeply about data literacy as we do. Bringing together our networks and expertise, we designed a bold new programme, organised in four data-literacy related areas: Data Journalism, Extractives Industries, Responsible Data and fellows’ “Own Focus”. In this way, we aim for School of Data to become a data-literacy hub, creating spaces in which both organisations and local leaders will engage with data literacy in new and exciting ways.
We are very proud to announce our School of Data Fellowship Class of 2016. We have reviewed 736 applications from 102 different countries. Our team worked around the clock to coordinate interviews across multiple timezones and our partner organisations and funders played a definitive role in identifying the best candidates.
We couldn’t be more happy with this class and we are sure they will make a huge splash in their respective regions! Here are the new School of Data fellows:
Nika Aleksejeva, Latvia

Nika is a passionate data storyteller from Latvia. In 2013, she joined Infogr.am, a popular data visualization service that empowers non-designers to create beautiful data visualizations in no time. In 2014, she launched the international Infogram Ambassador Network that unites ~100 data enthusiasts all over the world. Each of them brings the power of data visualisation to local communities worldwide. Nika comes from a journalism background – her work involved writing about business topics and data-driven stories about energetics, global economic trends and education. Seeing the future in digital journalism, she continues to work and share the knowledge that helps to develop new communication forms. Currently she works to empower Latvian journalists with data journalism skills by curating School of Data in Latvia.
She will join the Data Journalism track to empower data-literacy activities with Journalists in Latvia
Precious ONAIMO, Nigeria

Precious is a software developer and a technology enthusiast with the belief that people can only live better if they are provided with accurate, reliable and easy-to-access data, and tools that enable them to make real-time, qualitative and informed decisions. He was the Deputy Head of Software Development in iDevWorks Nigeria Limited, where he worked on designing, development and maintenance of many industry enterprise resource planning solutions geared towards eradicating the unavailability, insecurity, errors and delays associated with manual collation and distribution of organizational data and workflows. He currently heads a team of six programmers to develop open data solutions in different sectors, such as agriculture and extractives industries.
He will join the Extractives Data track and will work with the Nigerian team at the Natural Resources Governance Institute
Vadym Hudyma, Ukraine

Vadym Hudyma is an open data activist and works as digital security consultant for CSOs and activist groups in Kiev, Ukraine. He was involved in several projects focused on government, electoral and parliamentary transparency in Ukraine. It included mass screening tens of thousands of candidates in Parliament and local elections for their involvement in corruption crimes or human rights violation activities. He also worked on the launch of an extensive database of firms and individuals mentioned as suspects in anti-corruption journalist investigations in Ukraine. One of his main activities was devising policy on disclosure procedures. As a security specialist, he’s helping raise and spread awareness in basic digital security problems as well as privacy issues in digital age. He also helps young non-governmental organizations in devising their information security policies, as well as contributes as a trainer to journalists and activists working in the war zone in Eastern Ukraine and in annexed Crimea.
He will join the Responsible Data track and will be working with The Engine Room
Malick LINGANI, Burkina Faso

Malick Lingani is a Social Entrepreneur from Burkina Faso. He is committed to improving Transparency and Accountability through the advancement of Data Literacy within organizations, institutions and media. He is the Co-founder of the Ouagadougou-based NGO BEOG-NEERE.Org (For a better future) where he works as a data scientist and also as mentor to empower youth in the development of innovative and sustainable startups in sub-Saharan Africa since 2012. Malick holds a Master in Computer Sciences and Business development from the University of Ouagadougou and also a Data Science Specialization from John Hopkins University.
He will join the Extractives Data track and will work with the Natural Resources Governance Institute
Kabukabu MUHAU, Zambia

Kabukabu Muhau is a researcher and statistician specialised in demography and economics. She has worked with the NGO Coordinating Council (NGOCC) as Monitoring and Evaluation assistant. Currently, she works for the National Youth Development Council as a Hub Officer, assisting youths in her province to access information more easily. Having studied Health Demography, she developed a keen interest in the Health sector of Zambia. She’s particularly interested in strengthening her country’s current Health Information Management System so that it yields desired results. Her future plans include pursuing a Master’s degree in Public Health so as to strengthen her knowledge on the health sector.
She will join the “Own Focus” track working with the School of Data team in Health Data
Raisa Valda Ampuero, Bolivia

Raisa is passionate about the impact of new technologies and social networks in the social justice field. She started working as a Community Manager in the “SerBolivianoEs” campaign, led by UNDP in Bolivia, the first Bolivian digital campaign. Raisa was logistics coordinator in encounters for a more inclusive and participatory Bolivian digital space, “Conectándonos I – II”, funded by Global Voices and Hivos, in which indigenous communities, LGBT groups, women’s associations among others participated. Raisa also worked as Social Media Strategist of the digital platform “La Pública” project promoted by Hivos, that opens and manages spaces for active citizenship through social networks and outside them; she is an Open Data activist with Bolivian projects “Cuántas Más” and “Que no te la charlen””, the last one winner of Bolivia’s First Accelerator of Data Journalism.
She will join the “Own Focus” track working with the SocialTIC and the School of Data team with Gender Data
Daniel Villatoro, Guatemala

Daniel Villatoro started working as a journalist in Plaza Pública, an online media dedicated to do in depth journalism. There, he has worked in the Maps and Data section of the newspaper, as an investigative reporter and in other data driven projects. He graduated from Plaza Publica’s two year training program in 2014. His work has also been featured in other media like El Faro and Data Politica (El Salvador), Fáctico and Animal Politico (México) and Ojoconmipisto —a project about local corruption reporting in Guatemala’s municipalities—. He has a taste for maps, so he publishes some and tries to travel others. In 2014 he was part of the group that investigated the way the guatemalan government hid the deaths of kids who died due to malnutrition by analysing a database with all the death records of the country. In 2015 he did a series about political party financing by researching all the financial record data from the top three presidential candidates.”
He will join the Data Journalism track working with the SocialTIC team to bring data literacy to journalists in Central America
Ximena Villagrán, Guatemala

Ximena studied journalism in Guatemala and then a master’s degree in data and investigative journalism at El Mundo newspaper in Madrid, Spain. She’s currently working as a data reporter in Guatemala. Her beginning at data journalism was at the independent media outlet, Plaza Pública, where she discovered the power of data journalism to tell stories and began to learn more about it. By now she is exploring the power of open data and information access laws to create journalism tools available to all kind of people in Guatemala. Also, she is creating a model to include data journalism and visualizations in breaking news. In 2015, she worked at the data journalism unit of El Confidencial, Spain, where she learned about how to integrate a small data journalism unit into a traditional web newspaper. She also teaches data journalism at Universidad del Istmo in Guatemala, that has the best journalism school in the country.
She will join the Data Journalism track working with Internews and SocialTIC teams to bring data literacy to journalists in Central America
Omar Luna, El Salvador

Omar studied Social Communication at the Universidad Centroamericana “Jose Simeon Cañas” (UCA). He specialized in various areas such as quantitative and qualitative research, institutional communication, popular culture, proofreading, gender, among others. In 2008, he started working in different areas, such as education, journalism, research and collaboration. Two years ago, he found out the power of data as valuable inputs to evaluate speeches and traditional perspectives on many issues, such as gender violence and memory. Currently, he work as data consultant of the Business Intelligence Department at CentralAmericaData.com, one of the main business portals in Central America, for which he elaborate economic reports.
Omar will join the Data Journalism track working with Internews and SocialTIC teams to bring data literacy to journalists in Central America
The 2016 School of Data Fellowship is possible thanks to the generous help of the following partners & funders:
- Internews
- Hewlett Foundation
- Open Data for Development/International Development Research Centre
- Open Society Foundations
- Hivos
- Natural Resource Governance Institute
![]()