In our geocoding recipe, you learned how to use Google Sheets formulas to automatically convert place names into coordinates in your spreadsheet data. In this tutorial, you’ll learn how to take geocoding a step further, converting coordinates to GeoJSON boundaries—machine-readable descriptions of the boundaries of geographical regions like countries or provinces—using the Koordinates API. The Koordinates API takes latitude and longitude coordinates and returns boundary shapes that are on or near those coordinates.
In the geocoding recipe, you used built-in functions like ImportXML, CONCATENATE, and JOIN to get coordinates from place names using formulas like this:
=JOIN(",", ImportXML(CONCATENATE("http://open.mapquestapi.com/nominatim/v1/search?format=xml&q=",A2), "//place[1]/@lat | //place[1]/@lon"))
This formula is possible because the MapQuest API used in that tutorial returns XML data, which you can query using XPath strings like //place[1]/@lat with the built-in function ImportXML.
But Koordinates, the geospatial data API we’re using in this tutorial, returns its results in JSON rather than XML, and Google Docs doesn’t have any built-in functions to traverse JSON objects. Hence we’ll have to define our own.
To get started, you need to create an account with Koordinates and get an API key. To do create a key, log in, click on your name at the top of the page, select APIs and Web Services, and then click Accept terms and create key. Make a copy of the key that is generated—you’ll be using it soon.
Now go your spreadsheet, access the Tools menu, and select Script editor. Click Close to get rid of the dialogue box that appears. Once you’re in the script editor, delete the text from the edit box and then save your file, giving it a memorable name (perhaps Koordinates API function).
Now enter the following into the empty edit box, inserting your API key at the indicated spot:
function koords (coordsString) {
/* Block 1. Formats lat-long coordinates for Koordinates API call. */
coordsString = coordsString.replace(/\s/, "") ;
var coords = coordsString.split(",") ;
var xy = "&x=" + coords[1] + "&y=" + coords[0] ;
/* Block 2. Formats API call, makes API call, parses the result,
and stores the resulting object in "json". */
var key = "YOUR API KEY GOES HERE, INSIDE THESE QUOTATION MARKS" ;
var url = "http://api.koordinates.com/api/vectorQuery.json/?key=" + key + "&layer=1103&geometry=true" ;
var data = UrlFetchApp.fetch(url + xy) ;
var text = data.getContentText() ;
var json = JSON.parse(text) ;
/* Block 3. Traverses "json" to find boundary data and returns it. */
var result = json["vectorQuery"]["layers"]["1103"]["features"][0]["geometry"] ;
return JSON.stringify(result) ;
} ;
Let’s go through this code block by block.
The first block of code converts a string representation of latitude-longitude coordinates into the format Koordinates expects, with longitude in first place. It throws out any spaces in the string (replace), splits the string on the character ",", and glues it back together in the reverse order. It also gets it set up to be inserted into the Koordinates API call by placing the longitude value after "&y=" and the longitude after "&x=".
The next block sets up the URL for the API call and then makes the call. It asks for map layer 1103, which is a layer for country boundaries. It also requests “geometry”, meaning actual polygons (rather than just metadata, the default). The resulting JSON string is parsed into a JavaScript object with JSON.parse and put into the variable json.
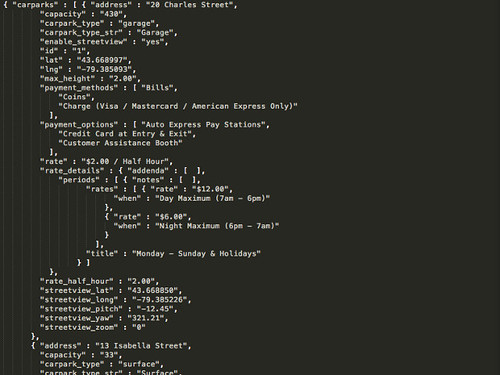
The JSON returned by the API looks like this:
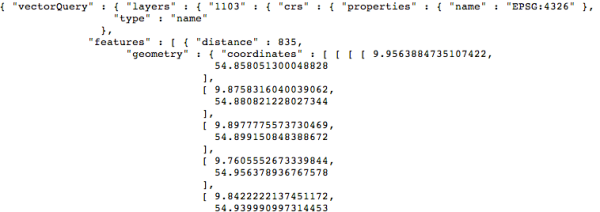
The polygon content we want, the “geometry”, is buried away deep inside the object. To get at it, we need to dig down through several layers of attributes. This is what the last block of code does, grabbing the "geometry" within the first item (item number 0) in the "features list of map objects returned for the query. It also turns the result into a string with JSON.stringify and returns it as the function’s value.
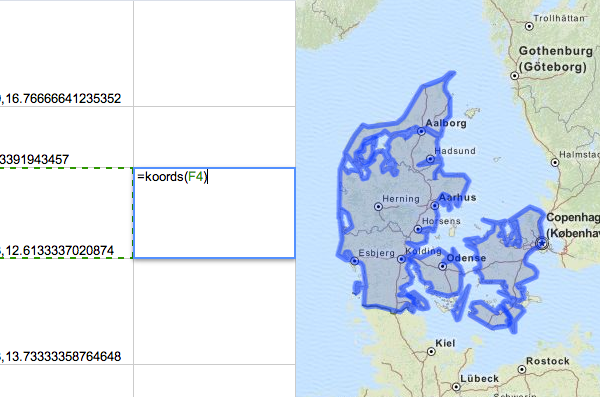
Try calling your new custom function, giving it the name of a cell that contains lat-long coordinates (here, F4):
=koords(F4)
You should get in return a blob of JSON data—the rich geometric representation of the country containing the point in F4.
You can now use koords like an ordinary Google Apps function. For example, you can wrap up the formula from the previous lesson to create a new formula that goes straight from place names to GeoJSON boundaries.
=koords(JOIN(",", ImportXML(CONCATENATE("http://open.mapquestapi.com/nominatim/v1/search?format=xml&q=",A2), "//place[1]/@lat | //place[1]/@lon")))
In this example, we used map layer 1103, which contains country boundaries. But Koordinates has many other layers which you might find useful. Check out the layers list to see what else you can do with the Koordinates API.