Authors: Vadym Hudyma, Pavlo Myronov. Part 1 of a series on Ukrainian student data.
Introduction
Ukraine has long been plagued with corruption in the university admission process due to a complicated and untransparent process of admission, especially for state-funded seats. To get it would-be students required not just a good grades from school (which also was subject of manipulation), but usually some connections or bribes to the universities admission boards.
Consequently, the adoption of External Independent Evaluation Testing (EIT) (as the primary criteria for admission into universities is considered one of a handful of successful anticorruption reforms in Ukraine. External independent evaluation is conducted once a year for a number of subjects, anyone with school diploma can participate in it. It is supervised by an independent government body (CEQA – Center for Educational Quality Assessment) with no direct links neither to school system nor major universities, All participant names are protected with unique code to protect results from forgery. {Explanation of the system in 1-2 sentence.}
The EIT has not eradicated corruption, but reduced it to a negligible level in the university admissions system. While its impact on the school curriculum and evaluation is, and should be, critically discussed, its success in providing opportunities for a bright student to get a chance to choose between the best Ukrainian universities is beyond doubt. Also, it provides researchers and the general public with a very good tool to understand, at least on some level, what’s going on with secondary education based on unique dataset of country-wide results of university admission tests.
Obviously, it’s also crucial that the results of the admission tests, a potentially life-changing endeavour, must be held as privately and securely as possible. Which is why we were stricken when the Ukrainian Center for Educational Quality Assessment (CEQA) also responsible for collecting and managing the EIT data, released this August a huge dataset of independent testing results from 2016.
In this case, this dataset includes individual records. Although the names and surnames of participants were de-identified using randomly assigned characters, the dataset was still full of multiple other entries that could link to exact individuals. Those include exact scores (with decimals) of every taken test subject, the birth year of each participant, their gender, whether they graduated this year or not and, most damning, the name of the place where each subject of external examination was taken – which is usually the schools at which participants got their secondary education.
I. Happy Experts
Of course, the first reaction from the Ukrainian Open Data community was overwhelmingly positive, helped with the fact that previous releases of EIT datasets were frustrating in their lack of precision and scope.
A Facebook post announcing the publication: “Here are the anonymized results of IET in csv #opendata”

*A Facebook comment reacting to the publication: “Super! Almost 80 thouthands entries” (actually more ;) *

A tweet discussing the data: “Some highly expected conclusions from IET data from SECA…”
As Igor Samokhin, one of the researchers who used the released EIT dataset in his studies, put it:
“[..This year’s] EIT result dataset allows for the first time to study the distribution of scores on all levels of aggregation (school, school type, region, sex) and to measure inequality in scores between students and between schools on different levels.[…] The dataset is detailed enough that researchers can ask questions and quickly find answers without the need to ask for additional data from the state agencies, which are usually very slow or totally unresponsive when data is needed on the level lower than regional.”
Indeed, the dataset made possible some interesting visualisations and analysis.
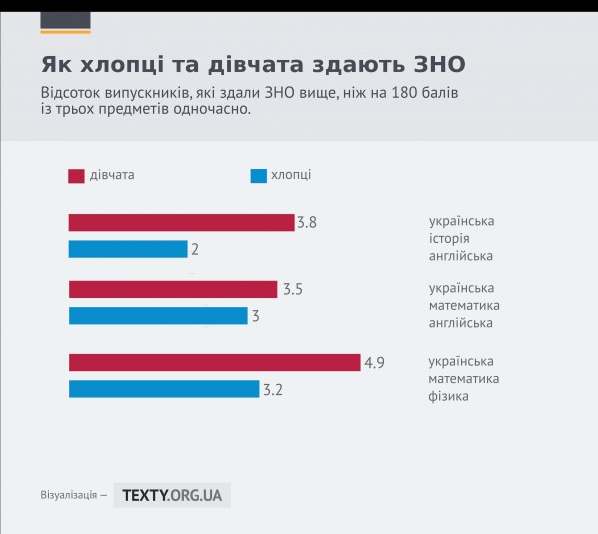
A simple visualisation showing differences in test results between boys and girls
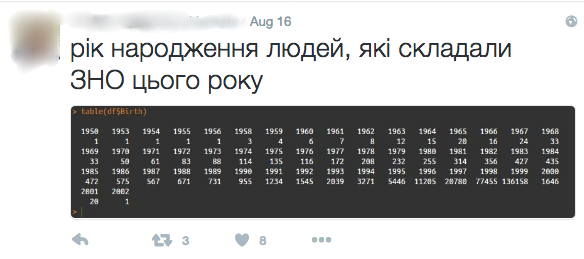
Quick analysis of birth years of those who took IET in 2016
But that amount of data and the variety of dimensions (characteristics) available carry many risks, unforeseen by data providers and overlooked by the hyped open data community and educational experts. We’ve made a short analysis of most obvious threat scenarios.
II. What could go wrong?
As demonstrated by various past cases across the world, microdata disclosure, while extremely valuable for many types of research such as longitudinal studies, is highly susceptible to re-identification attacks.
To understand the risks involved, we went through a process called threat modeling. This consists in analysing all the potential weaknesses of a system (here the anonymisation technique used on the dataset) from the point of view of a potential individual with malicious intentions (called’ attacker’). Three threat models emerged from this analysis:
The ‘Nosy neighbour’ scenario
The first and most problematic possibility is called the “nosy neighbour” scenario. This corresponds to an unexpected disclosure of results from relatives, neighbours, school teachers, classmates, or anyone with enough knowledge about an individual described in the dataset to recognize who the data describes – without having to look at the name. The risks involved with this scenario include possible online and offline harassment against people with too low or too high – depending on context – test results.
Unwanted disclosure may happen because members in the subject’s close environment can already have some additional information about the person. If you know that your classmate Vadym was one of the rare person of the village to take chemistry in the test, you can easily deduce which line of the data corresponds to him, discovering in the same way all the details of his tests results. And depending on what you (and others) discover about Vadym, the resulting social judgment could be devastating for him, all because of an improperly anonymised dataset.
This is a well-known anonymisation problem – it’s really hard to get a good anonymity with that many dimensions – in this case, the subject and exact results of multiple tests and their primary examination location.
It’s an especially alarming problem for schools in small villages or specialised schools – where social pressure and subsequent risk of stigmatisation is already very high.
The ‘Ratings fever’ problem
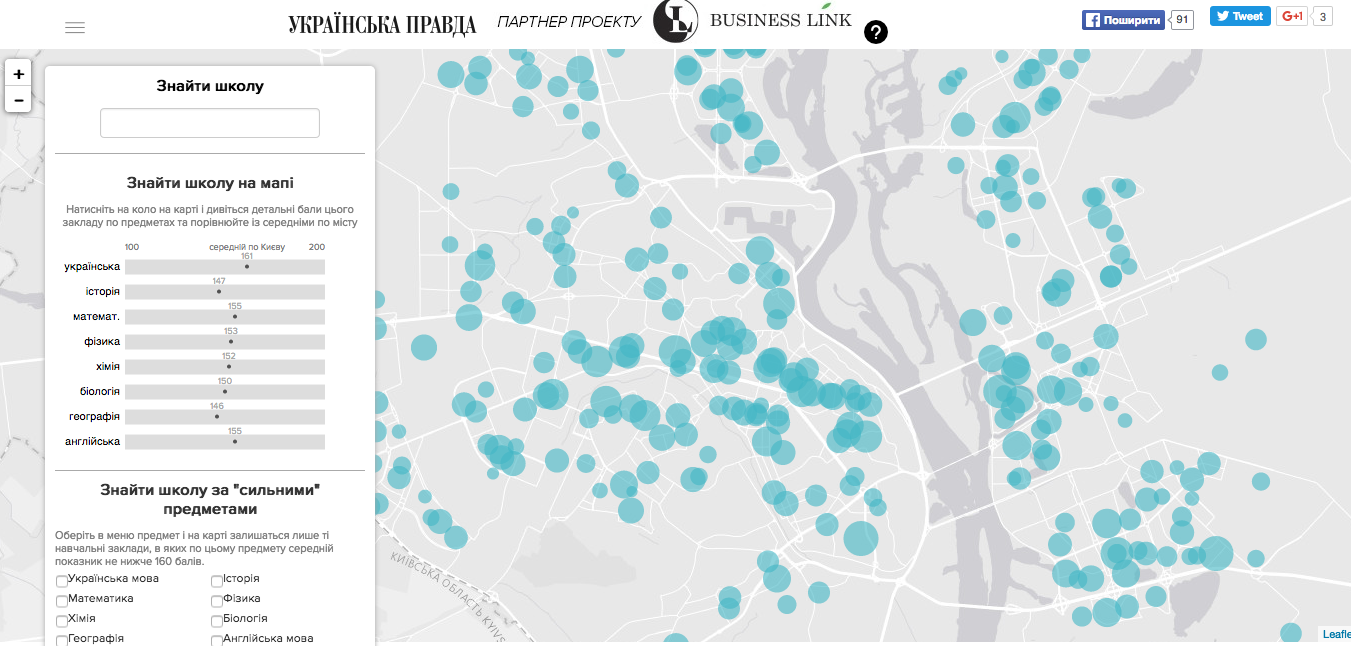
Map of schools in Kiev, Ukraine’s capital, made by the most popular online media based on EIT results
The second problem with educational data is hardly new and the release of this dataset just made it worse. With added precision and targeting power, more fervour was granted to the media’s favoured exercise of grading schools according to successes and failures of the external testing results of its students.
In previous years, many educational experts criticised ratings made by media and the different government authorities for incompleteness: they were based either on a full dataset, but for only one test subject, or were made using heavily aggregated and non-exhaustive data. But such visualisations can have consequences more problematic than misleading news readers about the accuracy of the data.
The issue here is about the ethical use of the data, something often overlooked by the media in Ukraine, who happily jumped on the opportunity to make new ratings. As educational expert Iryna Kogut from CEDOS explains:
“EIT scores by themselves can not be considered as a sign of the quality of education in a individual school. The new dataset and subsequent school ratings based on it and republished by CEQA only maintains this problem. Public opinion about the quality of teaching and parental choice of school relies on results of the EIT, but the authors of the rating do not take into account parents’ education, family income, the effect of private tutoring and others out-of-school factors which have a huge influence on learning results. Besides, some schools are absolutely free to select better students (usually from families with higher socioeconomic status), and this process of selection into “elite” schools is usually neither transparent nor fair. So they are from the start not comparable with the schools having to teach ‘leftovers’. ”
Even as people start understanding the possible harm of the “rate everything” mentality for determining both public policy and individual decisions, almost every local website and newspaper has made or republished school ratings from their cities and regions. In theory, there could be benefits to the practice, such as efforts to improve school governance. Instead, what seems to happen is that more students from higher-income families migrate to private schools and less wealthy parents are incentivised to use ‘unofficial’ methods to transfer their kids to public school with better EIT records. Overall, this is a case where the principle “the more informed you are the better” is actually causing harm to the common good – especially when there is no clear agenda or policy in place to create a fairer and more inclusive environment in Ukrainian secondary education.
Mass scale disclosure
The last and most long-term threat identified is the possible future negative impact on the personal life of individuals, due to the unwanted disclosure of test results. This scenario considers the possibility of mass scale unwanted identity disclosure of individuals whose data were included in recent EIT data set.
As our research has shown, it would be alarmingly easy to execute. The only thing one needs to look at is already-published educational data. To demonstrate the existence of the this threat, we only had to use one data set: close to half of the EIT records could be de-anonymised with varying level certainty, meaning that we could find the identity of the individual behind the results (or narrow down the possibility to a couple of individuals) for one hundred thousand individual records.
The additional dataset we used comes from another government website – vstup.info – which lists all applicants to every Ukrainian university. The data includes the family names and initials of each applicant, along with the combined EIT results scores. The reason behind publishing this data was to make the acceptance process more transparent and cut space for possible manipulations.
But with some data wrangling and mathematical work, we were able to join this data with the IET dataset, allowing a mass scale de-anonymisation.
So what should be the lessons learned from this?
First, while publishing microdata may bring enormous benefits to the researchers, one should be conscious that anonymisation may be really hard and non-trivial problem to solve. Sometimes less precision is needed to preserve anonymity of persons whose data is included in the dataset.
Second – it’s important to be aware of any other existing datasets, which datasets may be used for de-anonymization. It’s responsibility of data publisher to make sure of that before any information sharing.
Third – it’s not enough just to publish dataset. It’s important to make sure that your data wouldn’t be used in obviously harmful or irresponsible manner, like in various eye-catching, but very damaging in the long run ratings and “comparisons”.









 This episode features a one on one conversation with Daniela Lepiz, a Costa Rican data journalist and trainer, who is currently the Investigation Editor for CENOZO, a West African Investigative Journalism Project that aims to promote and support cross border data investigation and open data in the region. She has a masters degree in data journalism from the Rey Juan Carlos University in Madrid, Spain. Previously involved with OpenUP South Africa working with journalists to produce data driven stories. Daniela is also a trainer for the Tanzania Media Foundation and has been involved in many other projects with South African Media, La Nacion in Costa Rica and other international organisations.
This episode features a one on one conversation with Daniela Lepiz, a Costa Rican data journalist and trainer, who is currently the Investigation Editor for CENOZO, a West African Investigative Journalism Project that aims to promote and support cross border data investigation and open data in the region. She has a masters degree in data journalism from the Rey Juan Carlos University in Madrid, Spain. Previously involved with OpenUP South Africa working with journalists to produce data driven stories. Daniela is also a trainer for the Tanzania Media Foundation and has been involved in many other projects with South African Media, La Nacion in Costa Rica and other international organisations.
