Discover patterns in hundreds of documents with DocumentCloud
Daniel Villatoro - August 20, 2016 in Fellowship, HowTo
If you’re a journalist (or a researcher), say goodbye to printing all your docs in a file, getting them into a folder, and highlighting those with markers, adding post-its and labels. This heavy burden of reading, finding repeated information and highlighting it can be done for you by DocumentCloud: it allows you to reveal the names of the people, places and institutions mentioned in your documents to line up dates in a timeline, to save your docs on the Cloud in a private way – and with the option to make them public later.
DocumentCloud is an Open Source platform, and journalists and other media professionals have been using it as online archive of digital documents and scanned text. It provides a space to share source documents.
A major feature of DocumentCloud is how well it works with printed files. When you upload a PDF scanned as an image, the platform will read it with Optical Character Recognition (OCR) to recognize the words in the file. This allows investigative journalists to upload documents from original sources and make them publically accessible, and for the documents to be processed much more easily.
Some other features include:
- Running every document through OpenCalais, a metadata technology from Thomson Reuters that aggregates other contextual information to the uploaded files. It can take the dates from a document and graph them in a timeline or help you find other documents related to your story.
-
Annotating and highlighting important sections of your documents. Each note that you add will have its own unique URL so that you can have all in order.
-
Uploading files in a safe and private manner, but you have also the option to share those documents, make them public, and embed them. The sources and evidence of an investigation don’t have to stay in the computer of a journalist or the archives of a media organization – they can go public and become open.
-
Review of the documents that other people have uploaded such as files, hearing transcripts, testimony, legislation, reports, declassified documents and correspondence.
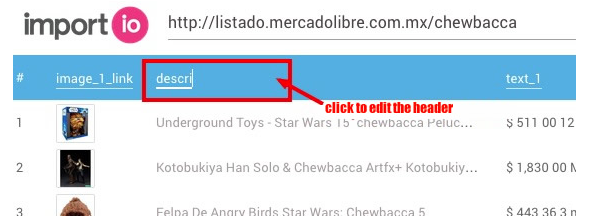
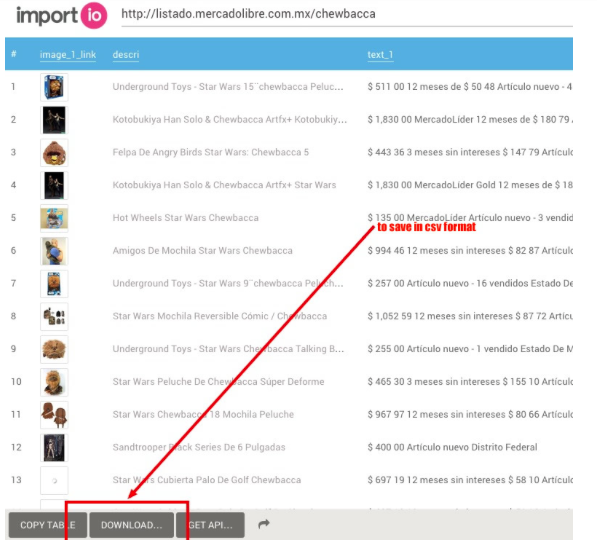
The platform in action
A while ago, an investigation on the manipulation of the buying system at the Guatemalan social insurance revealed a network of attorneys, doctors, specialists and associations of patients that forced the purchase of certain medicines for terminal patients. It was led by Oswaldo Hernández from *Plaza Públic*a, and DocumentCloud was at the core of the investigation process.
“I searched for words like ‘Doctor’ or ‘Attorney’ to find out the names of the people involved. That way I was able to put together a database and the relationships between those involved. It’s like having a big text document where you can explore and search everything”, explains Hernández.
When analysing one of the documents about medicines, DocumentCloud shows the names of people and institutions that are repeated in the text in a graphic plot.
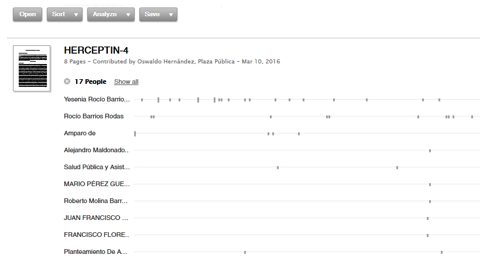
A screenshot of the graphic analysis that DocumentCloud plots from the uploaded files
Four creative uses of DocumentCloud
Below are some examples of how you can produce different types of content when you mix uploaded information, creativity and the functions of this tool.
The platform VozData, from the Argentinian newspaper La Nación, combines their own code with the technology of DocumentCloud to set up an openly collaborative platform that transforms Senate expense receipts into open and useful information by crowdsourcing it.
Due to the fact that their investigation about violence in a prison got published in The New York Times, *The Marshall Projec*t did a follow-up about how the prison officers censored the names of some guards and interns, and also aerial photos of the prison when the newspaper was distributed to prisoners.

The I*nternational Consortium of Investigative Journalists *(ICIJ) uses DocumentCloud so that readers can access the original documents of the Luxembourg Leak, secret agreements that reduced taxes to 350 companies across the world and approved by the Luxembourg authorities.
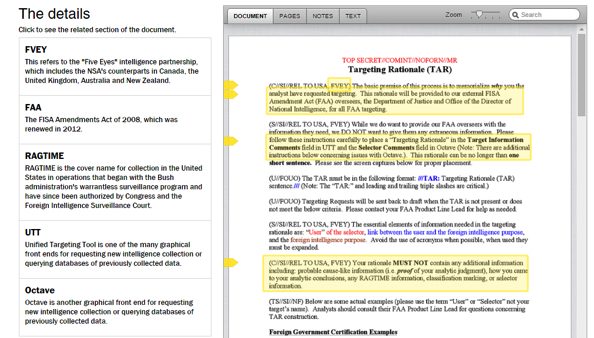
The* Washington Post *used the software to explain the set of instructions that the US National Security Agencys gives to their analysts, so that whenever they fill a form to access databases and justify their research, they don’t reveal too much suspicious or illegal information.
So, next time, when you have to do tons of research using original documents, you can make it publicly available through DocumentCloud. And, even if you’re not a journalist, you can still use this tool to browse their extensive catalogue of documents uploaded by journalists across the world.
![]()